Lecture: Gradient Boosting Machine
Actuarial Data Science - Open Learning Resource
Review: Bagging and Random Forests

Leo Breiman (1928–2005) (Source: Wikipedia)
- Deep trees (fine subgroups) are more accurate but very noisy.
- Idea: fit many different trees and average their predictions.
- Grow trees on bootstrap subsamples of the data
- Randomly select variables/features as candidates for splits
Example: Bootstrap Trees
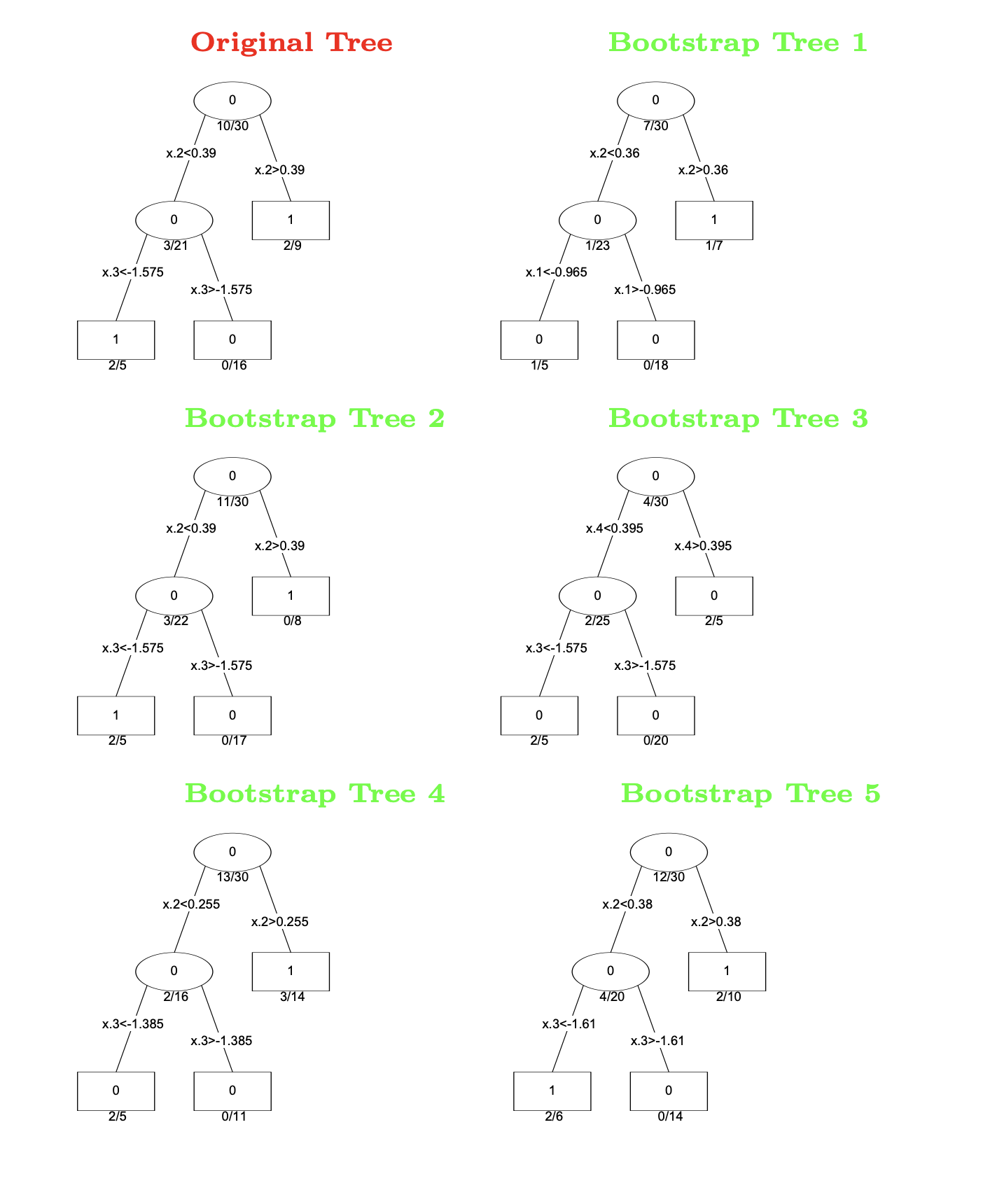
Different trees fitted on bootstrap samples.
Schematic of AdaBoost
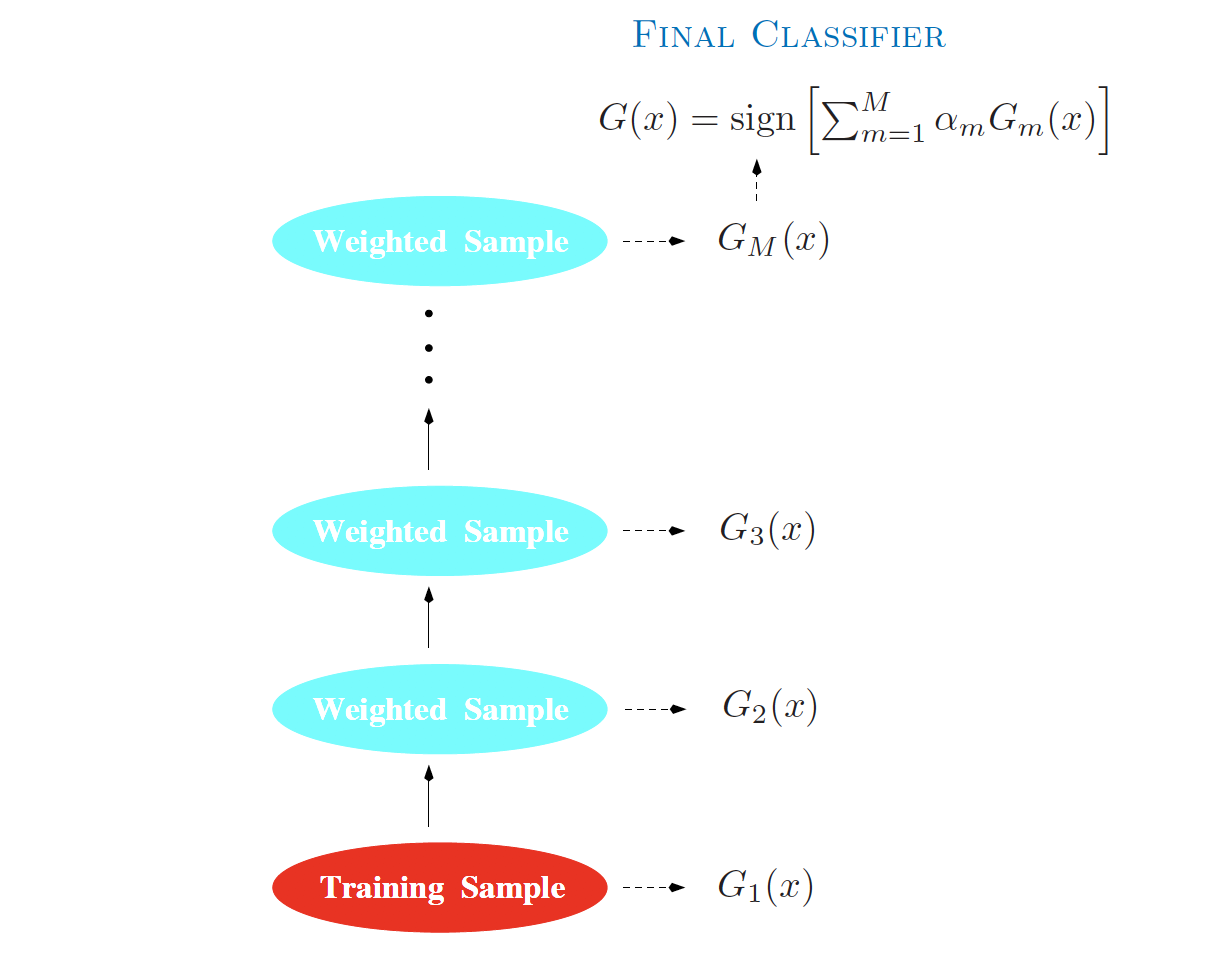
Schematic of AdaBoost (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 10.1).
Example: Boosting Stumps
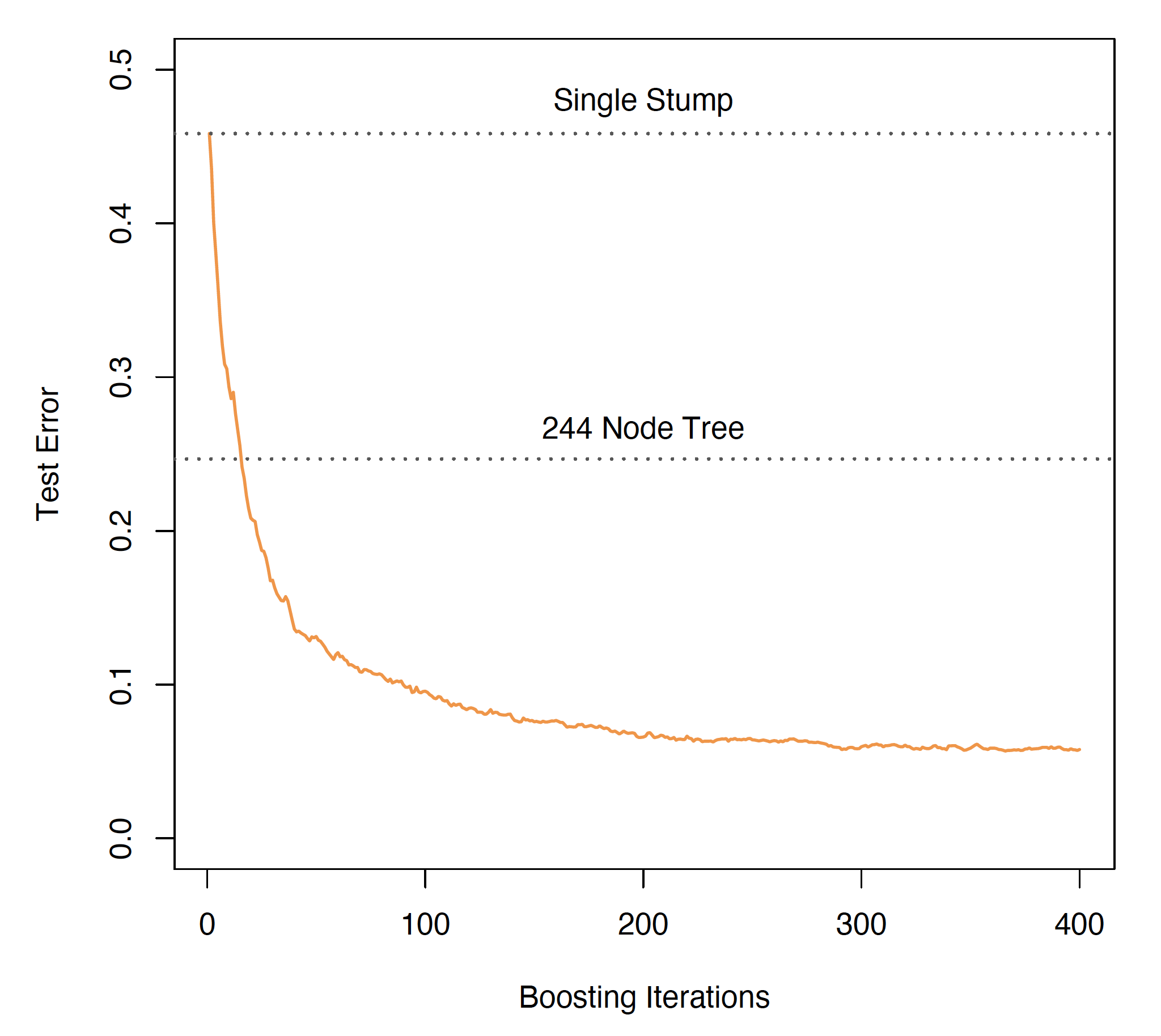
Test error versus boosting iterations for decision stumps (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 10.2).
- A very weak classifier.
- A stump is a two-node tree with a single split.
- Boosting stumps works remarkably well.
Training Error vs. Testing error
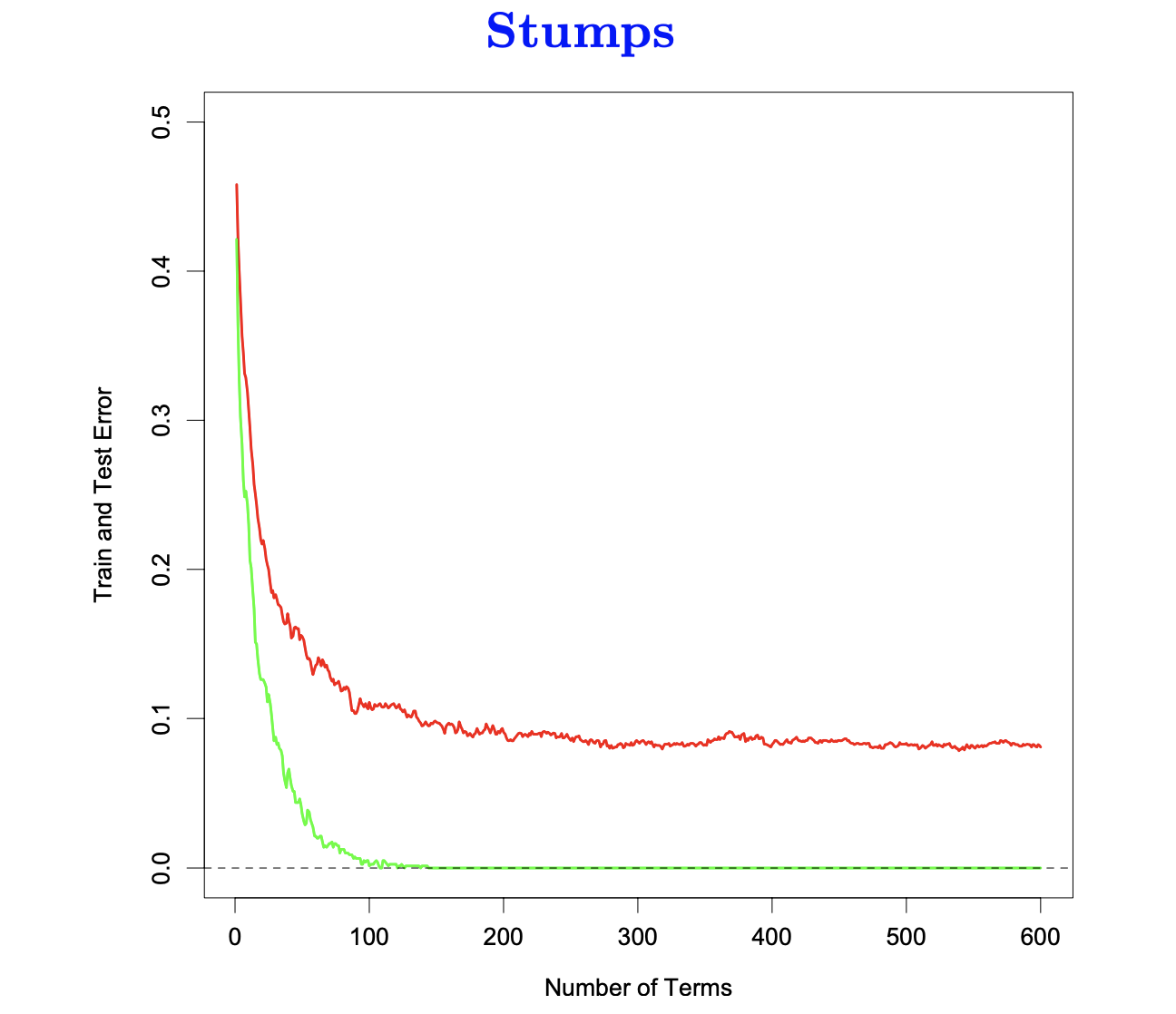
Training and test error as a function of the number of boosting iterations.
- Boosting drives the training error (green) towards zero.
- Further iterations often continue to improve the test error (red).
- Does boosting overfit?
Boosting in Noisy Problems
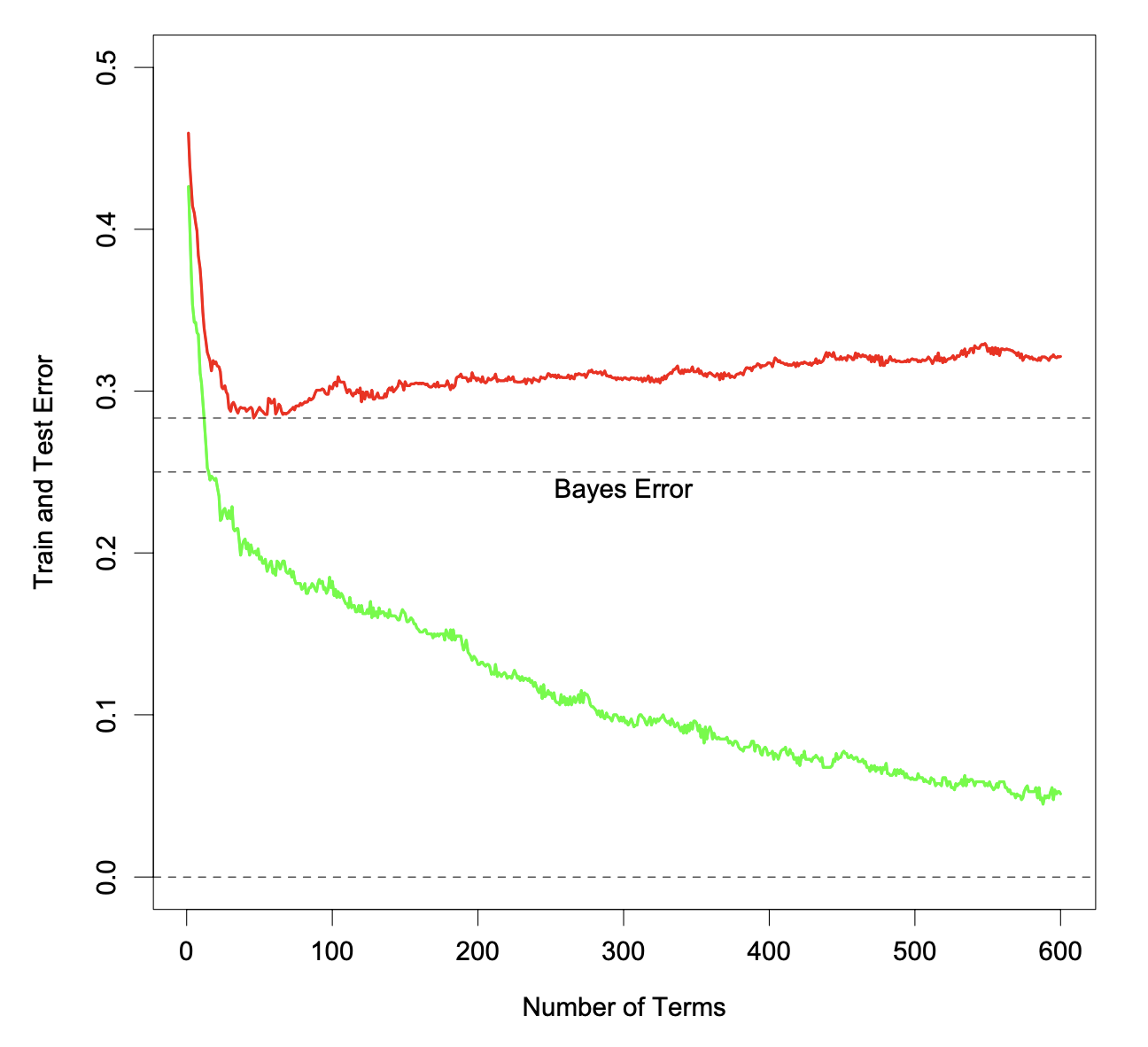
Training and test error as a function of the number of boosting iterations (noisy setting).
- The test error increases (slowly) as boosting iterations proceed.
Performance Comparison
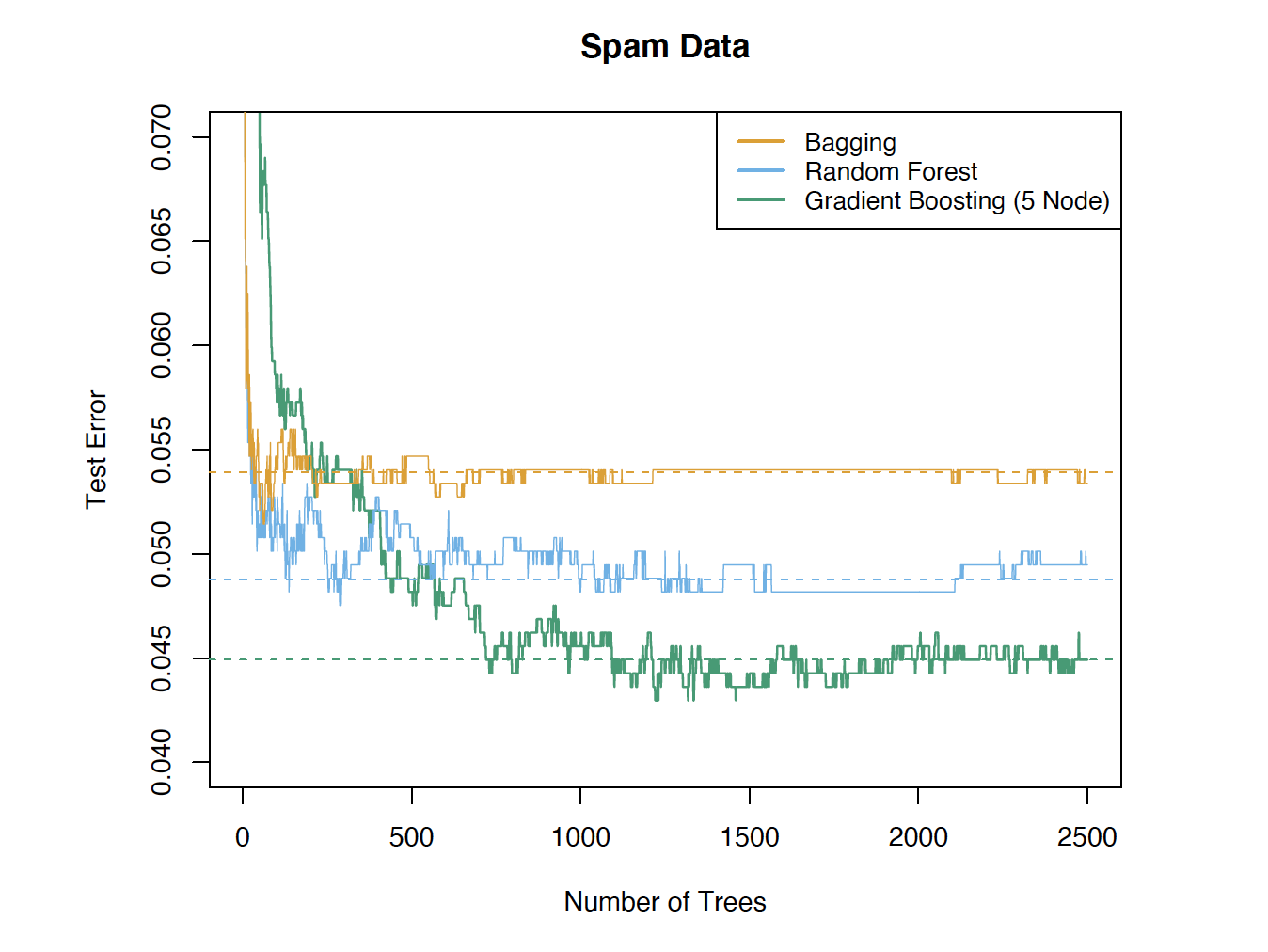
Test error versus number of trees for bagging, random forests, and gradient boosting (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 15.1).
Gradient Decent: The Effect of \gamma
- The step size |\mathbf{x}_{i+1} - \mathbf{x}_i| increases as \gamma increases.
- However, this does not mean the optimum is reached more quickly (the algorithm may oscillate).
- \mathbf{x}_i may even diverge if \gamma is too large.
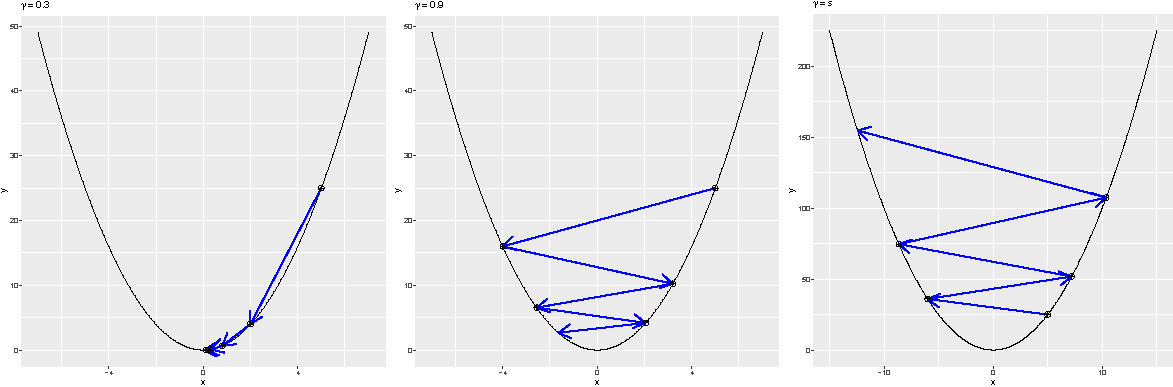
Effect of the learning rate \gamma in gradient descent. Left: \gamma=0.3 and x_5 is close to the solution; middle: \gamma=0.9, where larger steps still leave \mathbf{x}_5 far from the optimum; right: \gamma=1.1, where the iterates diverge.
Variable Importance Plot: Email Spam Prediction
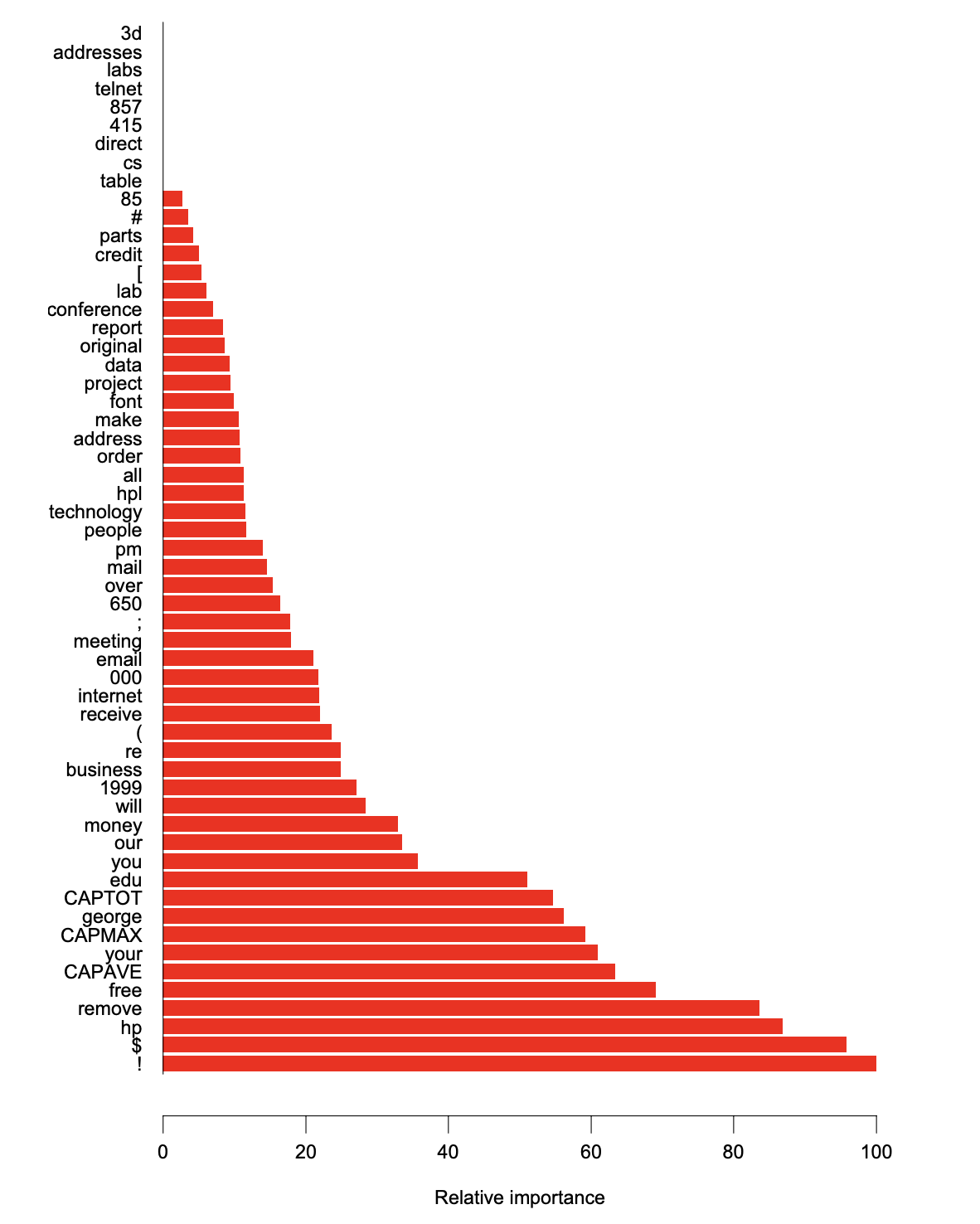
Variable importance (spam data, GBM) (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 10.6).
Partial Dependence Plot: Email Spam Prediction
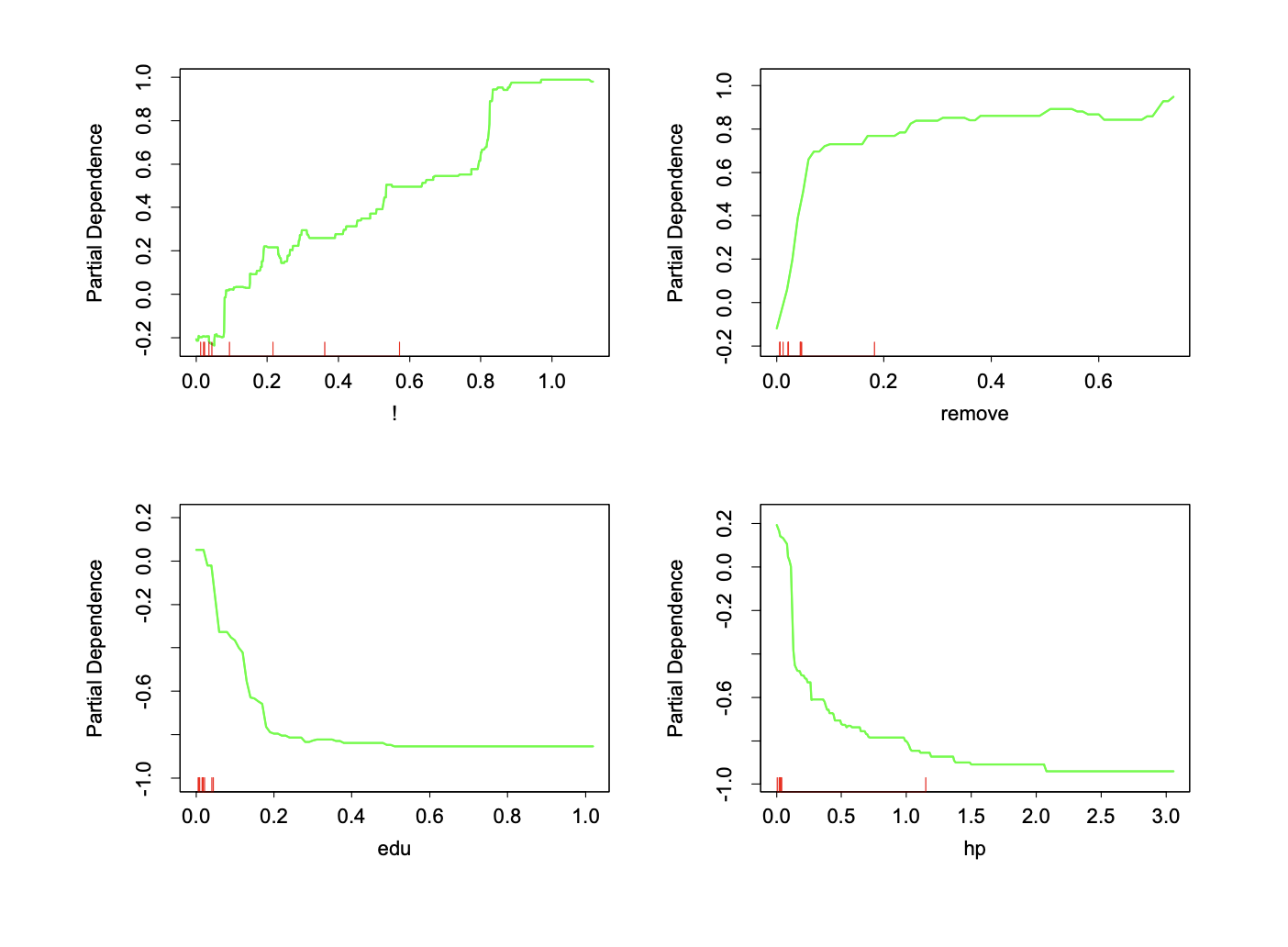
Partial dependence plots (spam data, GBM) (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 10.7).
References
![]()