Lecture: Random Forests
Actuarial Data Science - Open Learning Resource
A Classification Example Using CART
Classifying the iris data using CART (Source: Flower images are from Wikipedia)
A Regression Example Using CART
- The
Hittersdataset: predict a baseball player’s log salary based onYearsandHits
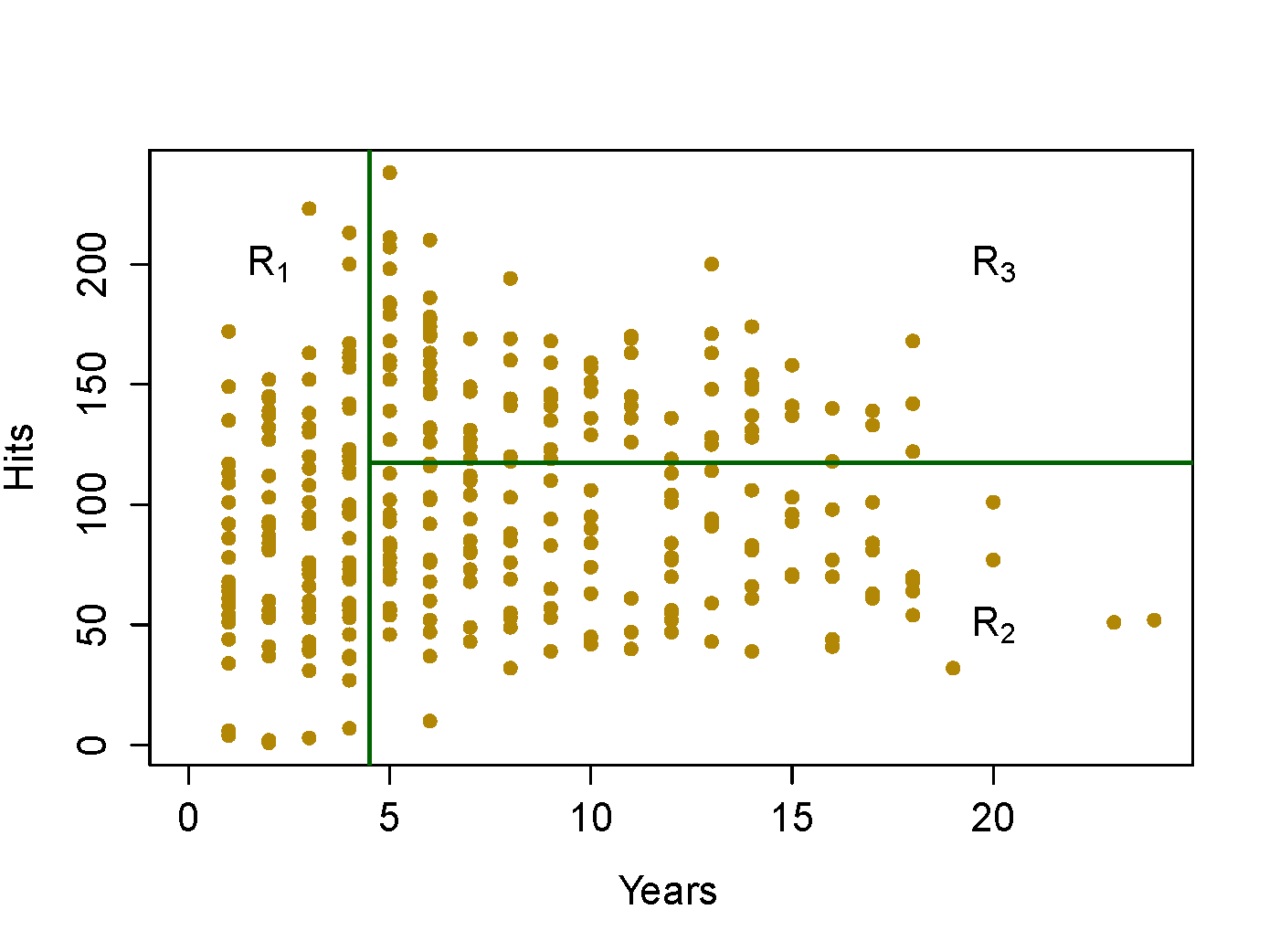
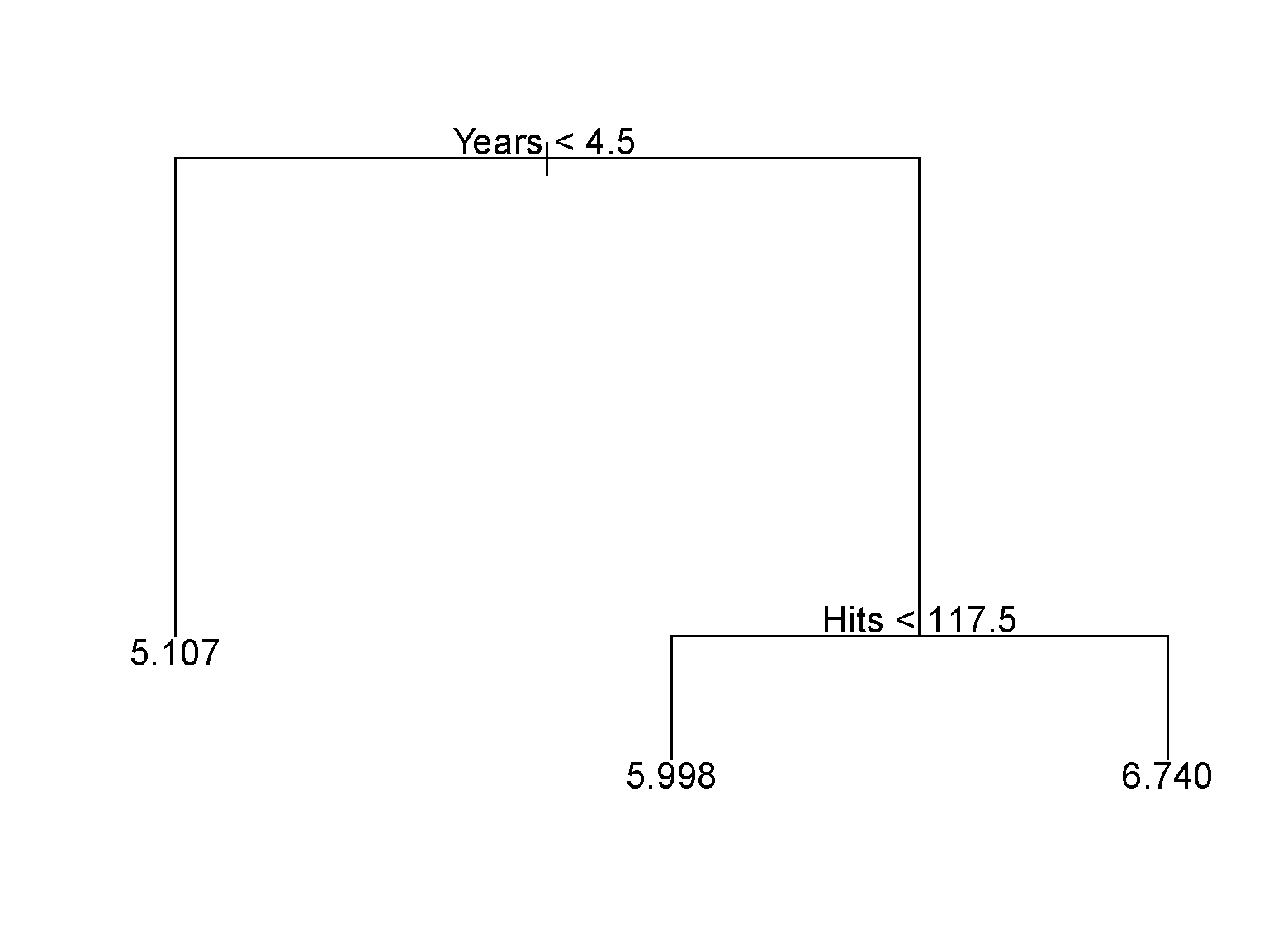
Partition Criteria: Classification (continued)
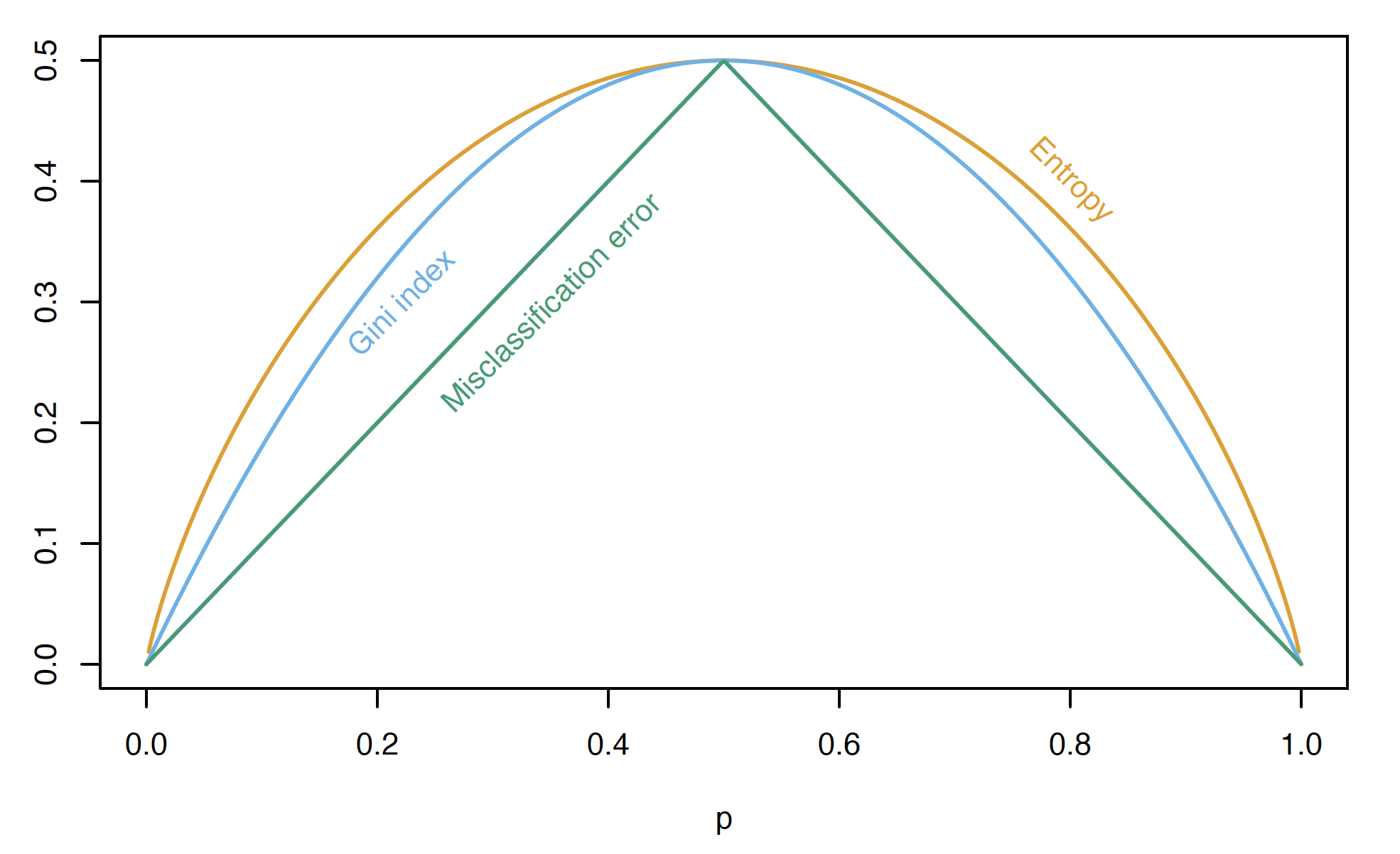
Comparison of impurity measures for two-class classification (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 9.3).
Classification and Regression Tree (CART)
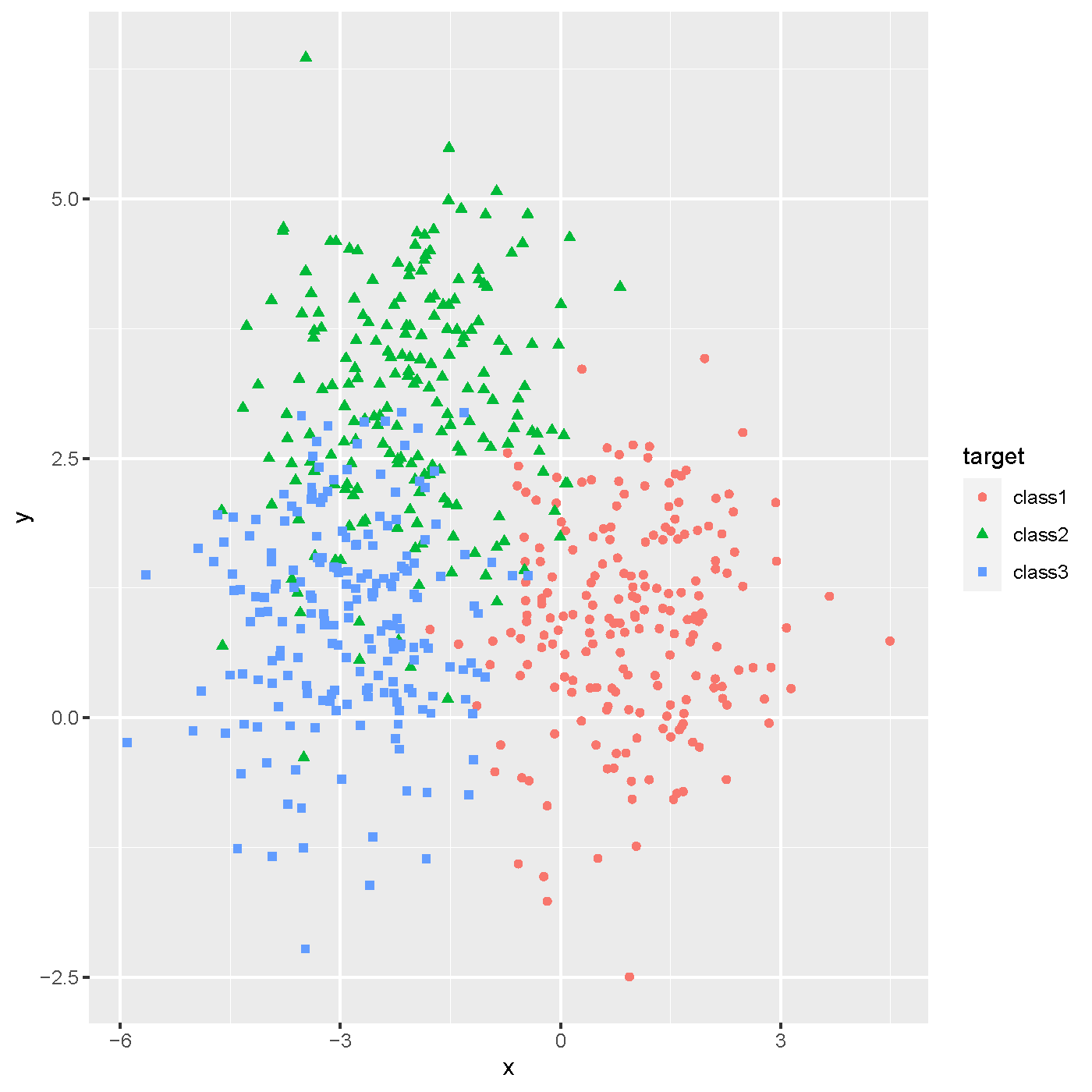
Simulated data with three classes.
Classification and Regression Tree (CART)
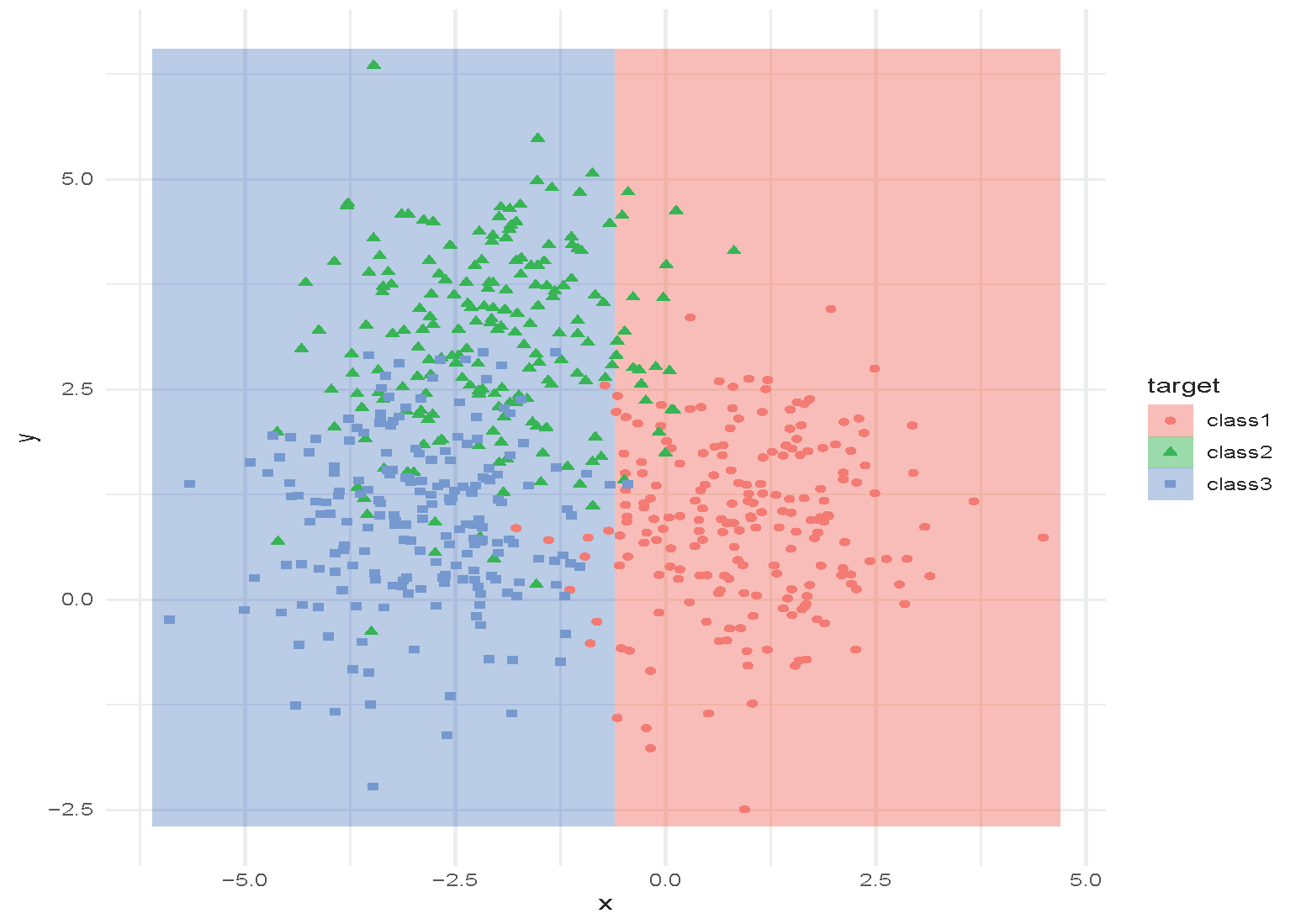
Tree with depth = 1.
Classification and Regression Tree (CART)
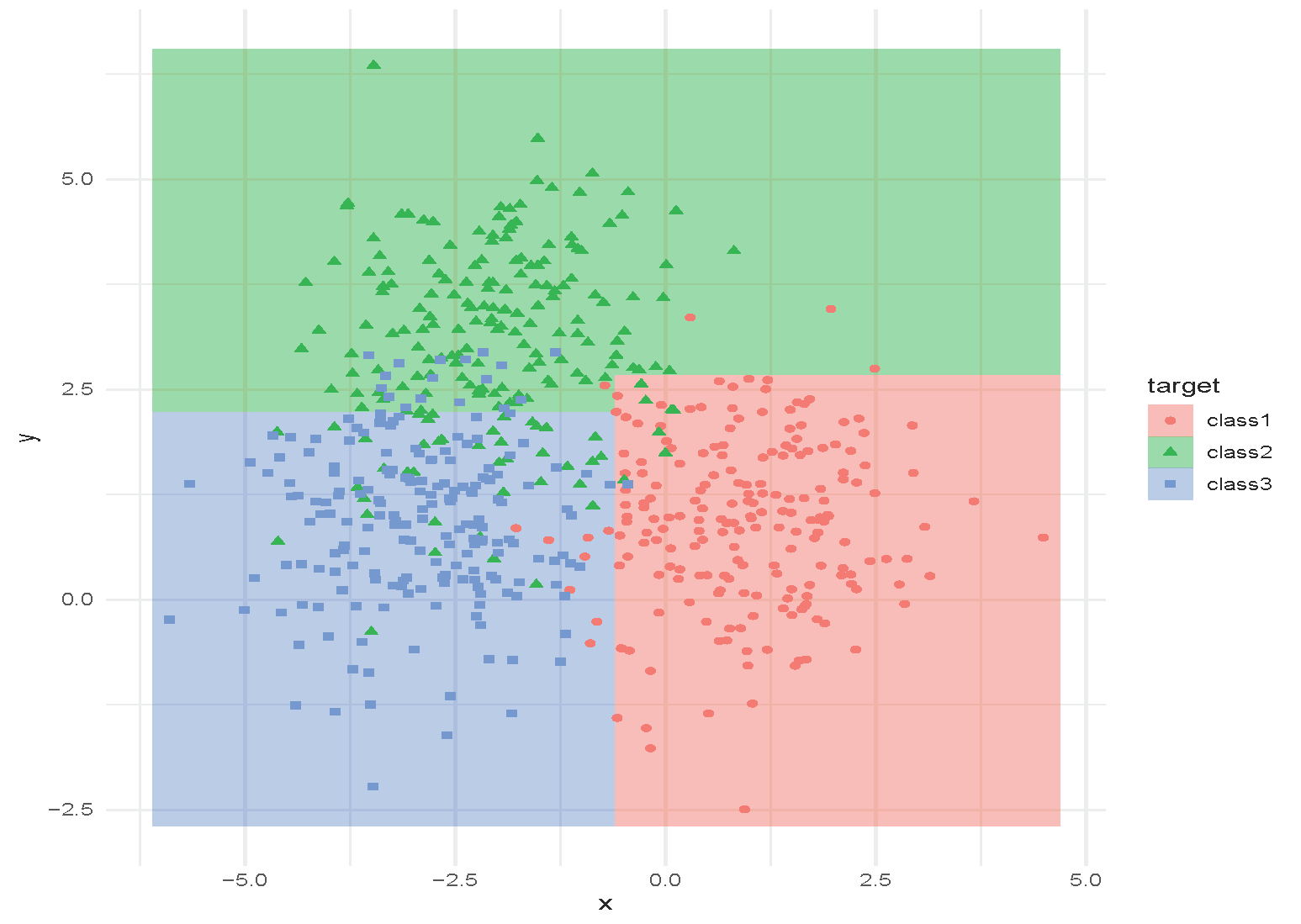
Tree with depth = 2.
Classification and Regression Tree (CART)
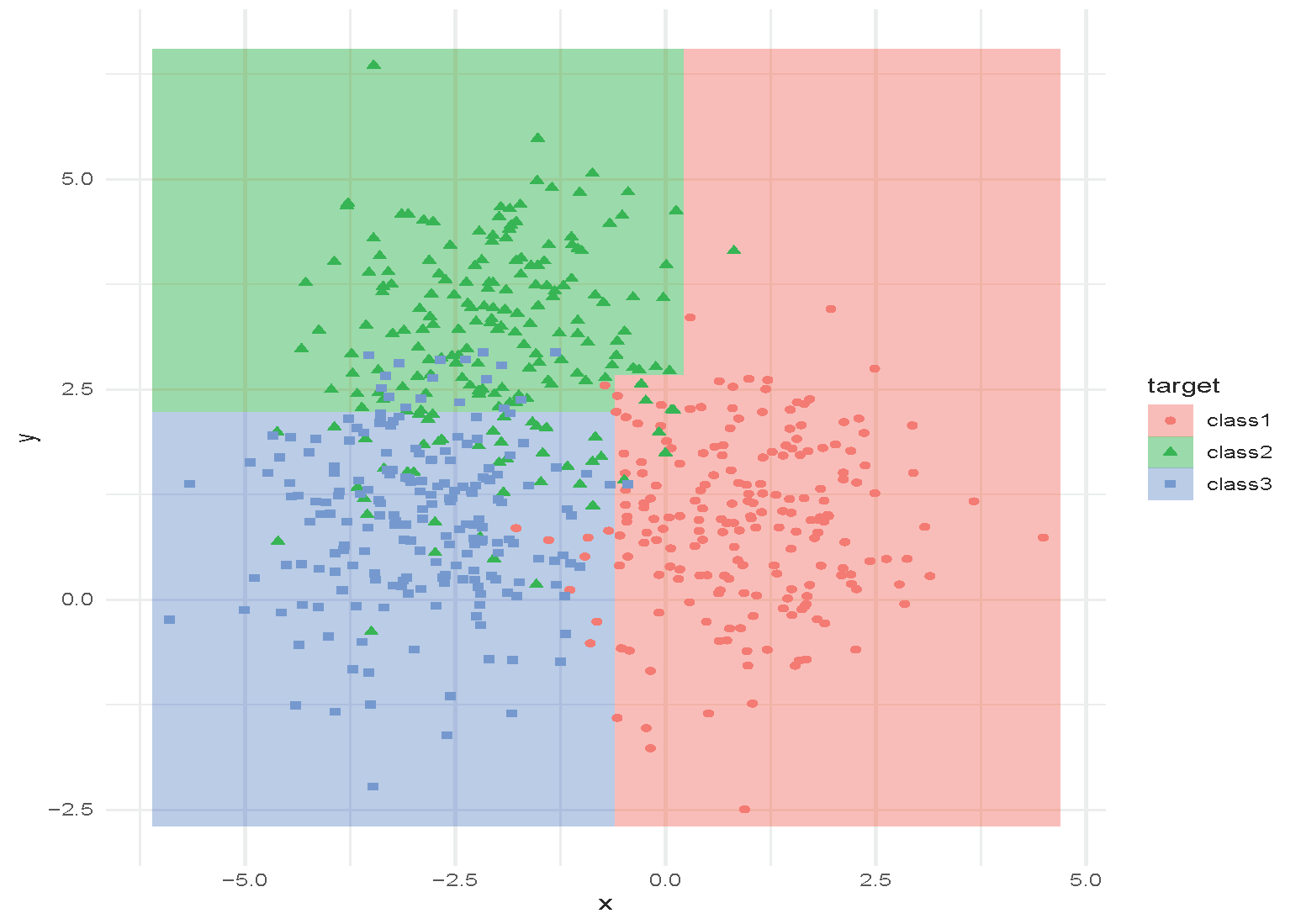
Tree with depth = 3.
Classification and Regression Tree (CART)
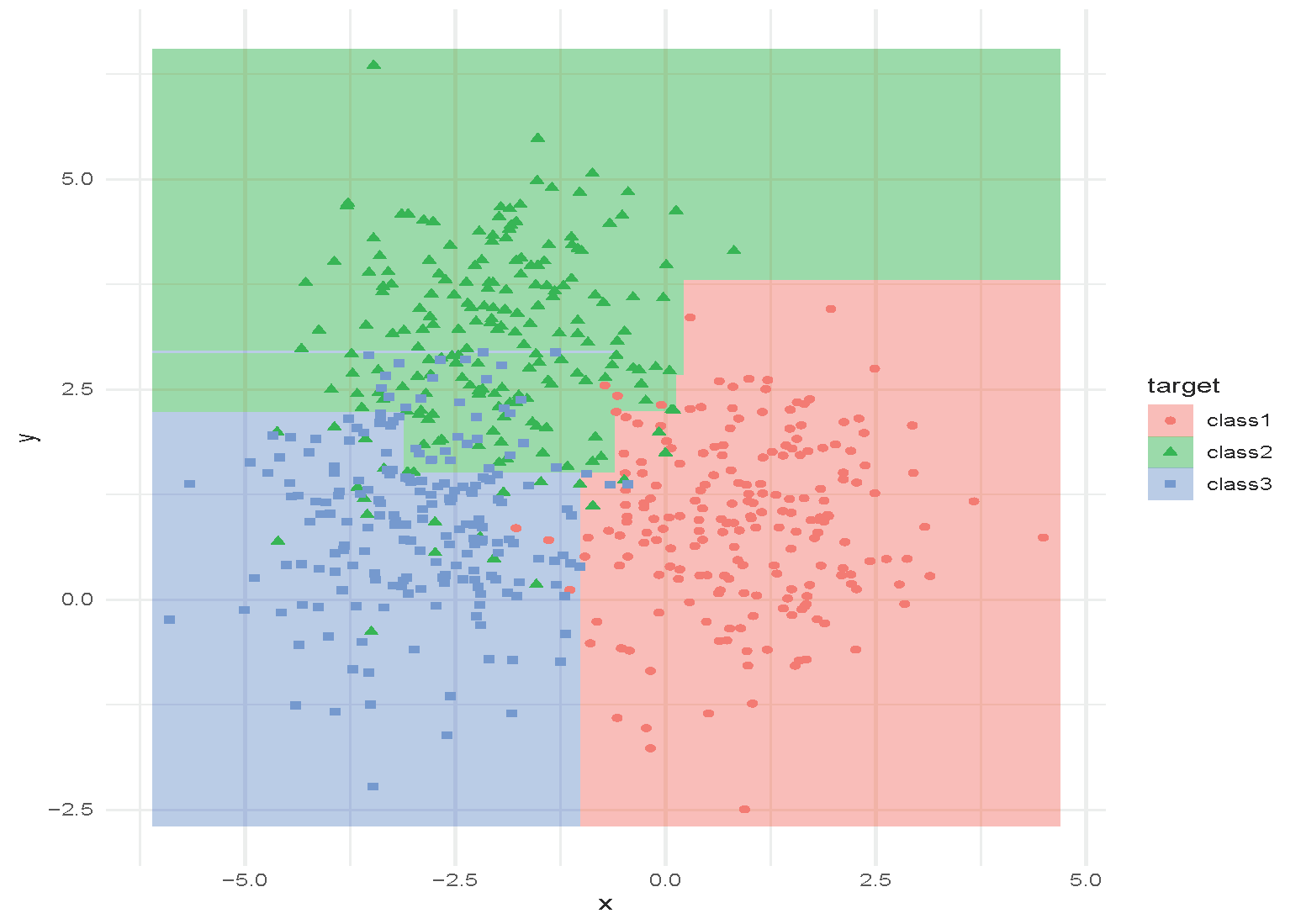
Tree with depth = 4.
Classification and Regression Tree (CART)
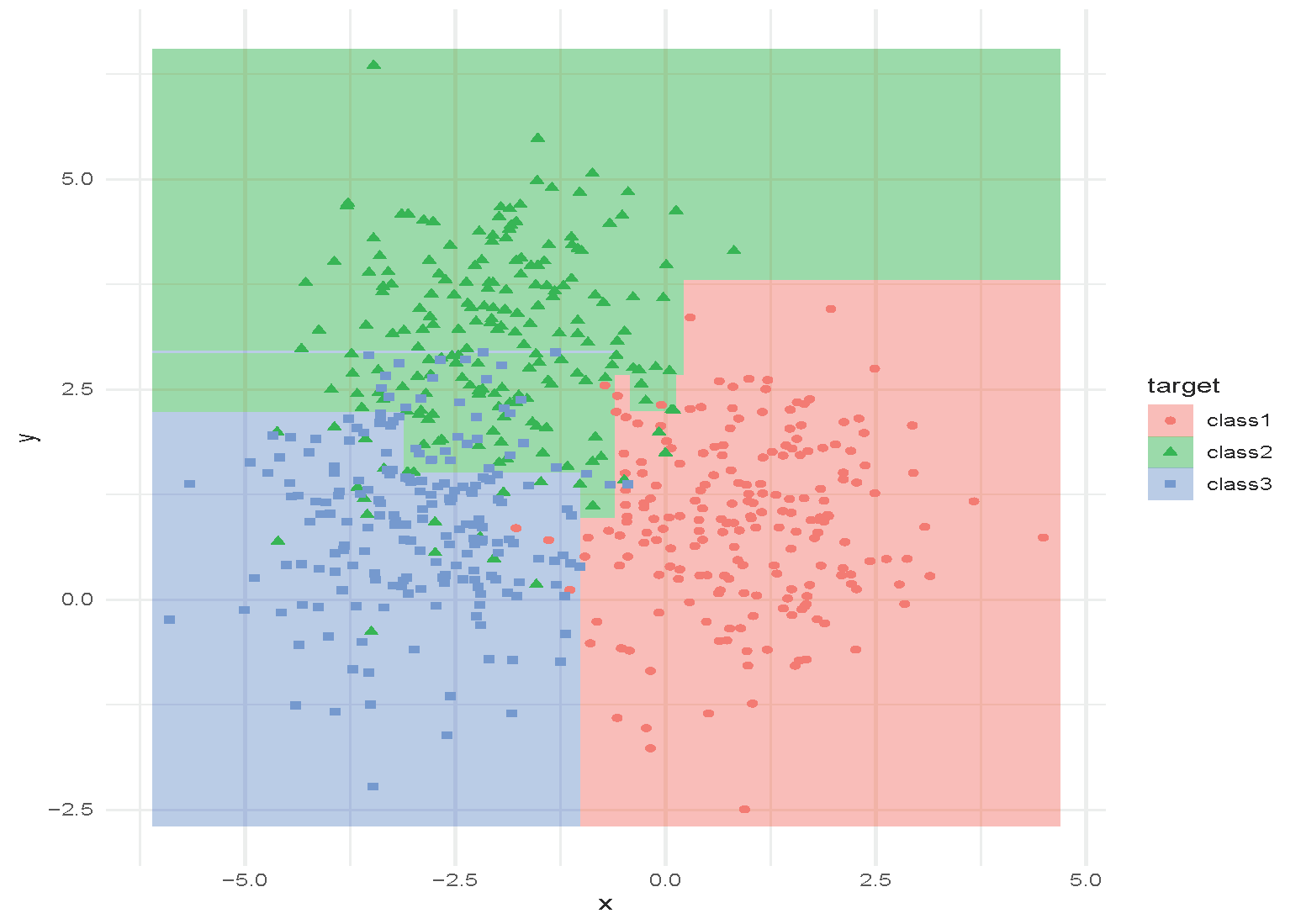
Tree with depth = 5.
Classification and Regression Tree (CART)
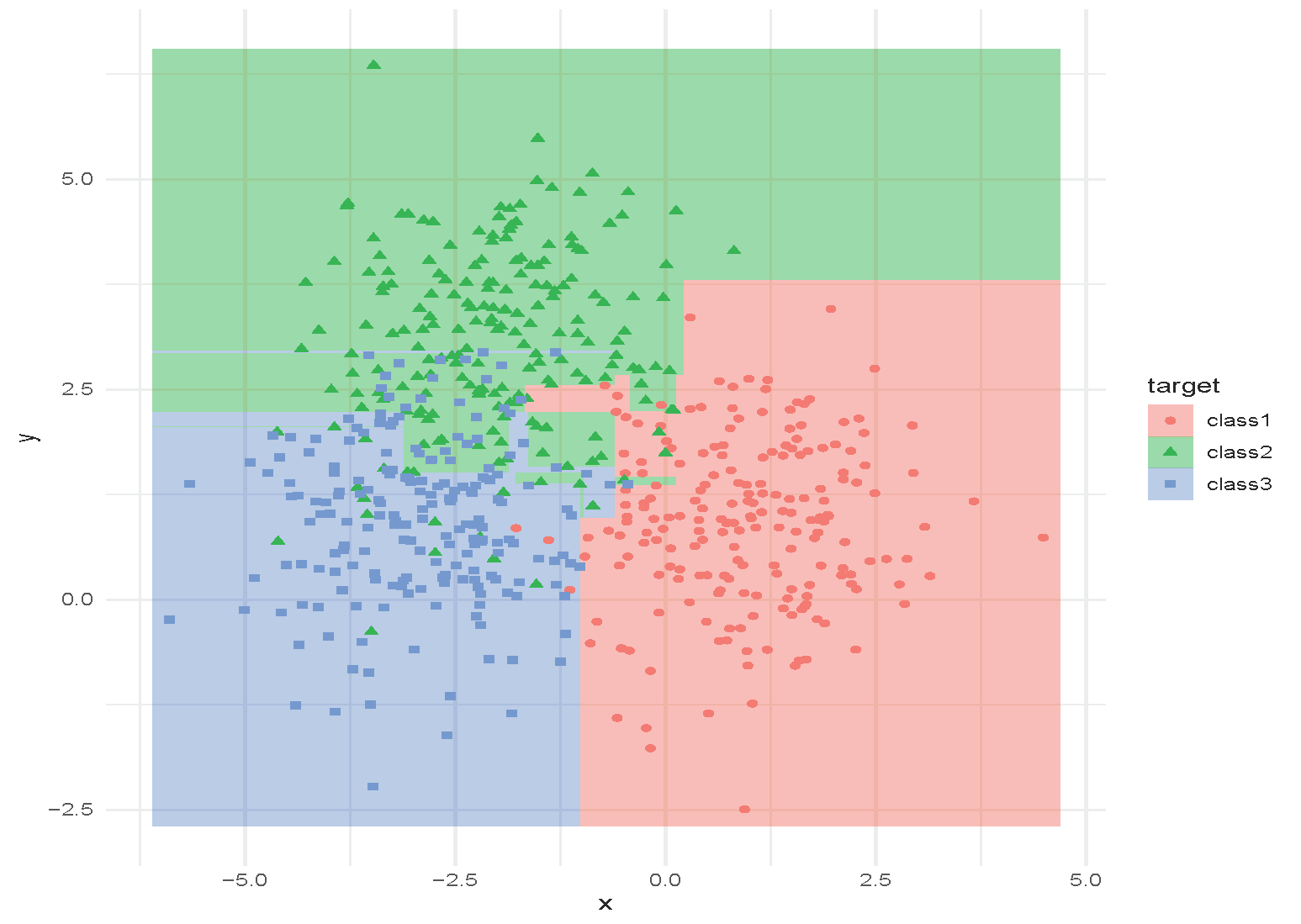
Tree with depth = 6.
Classification and Regression Tree (CART)
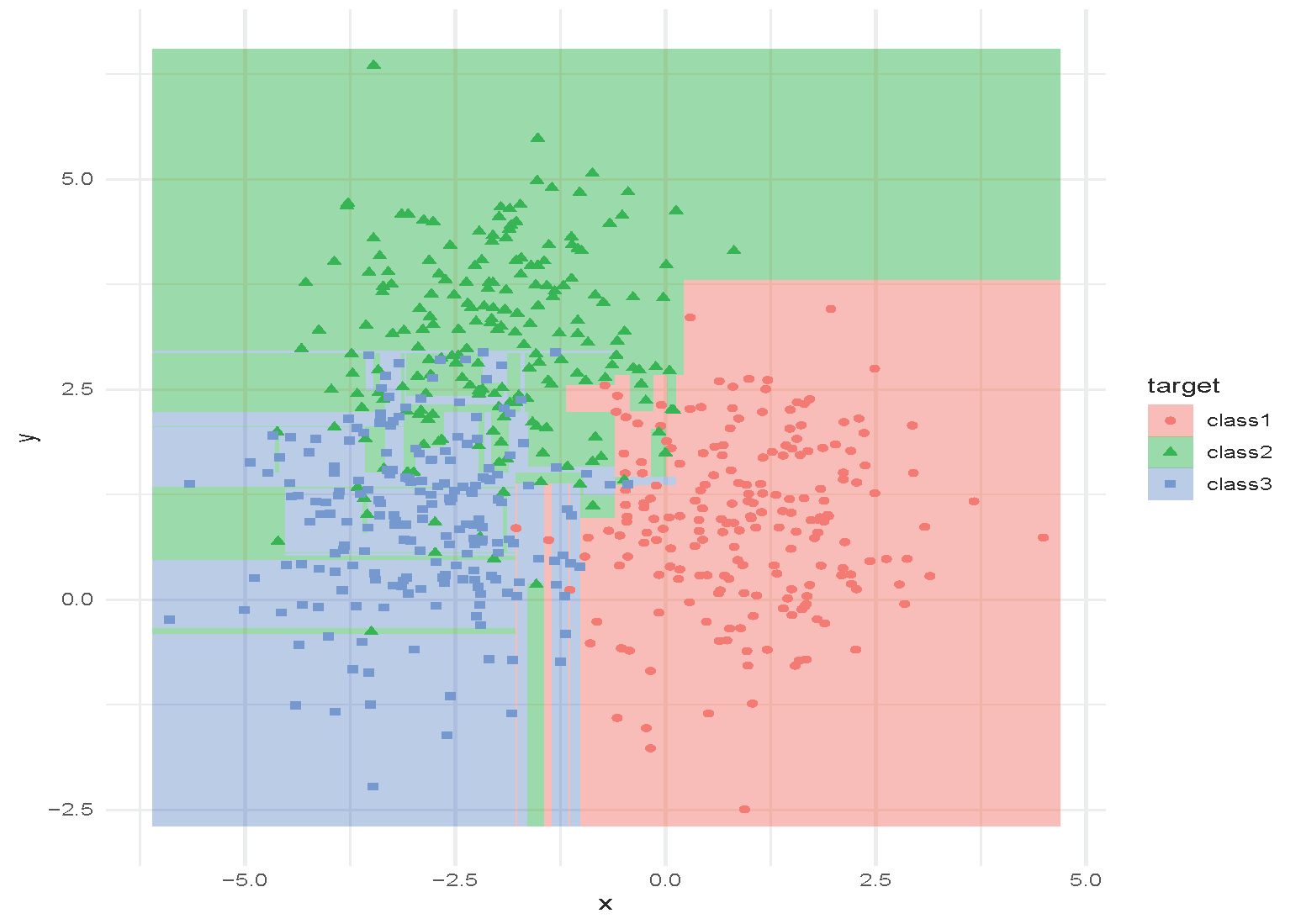
Tree with depth = 15.
[Add a example picture of Regression Tree here]
Another Illustration
- Bagging three CARTs (T_1, T_2, T_3) in binary classification.
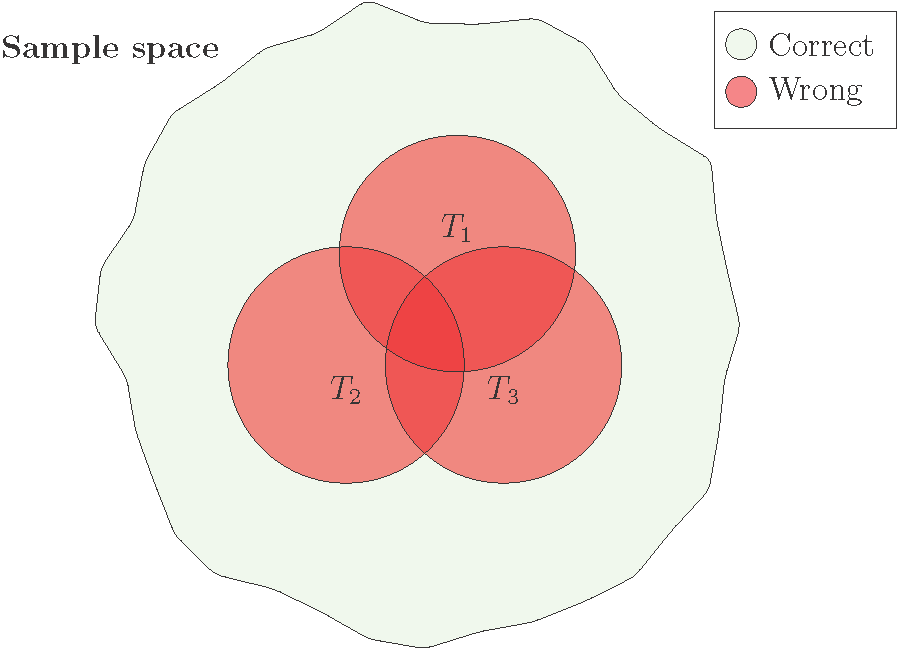
Illustration of bagging with three CART models: overall performance improves when the error regions overlap less.
- The overall performance is better when the error regions (red circles) overlap less.
An Example of Random Forest
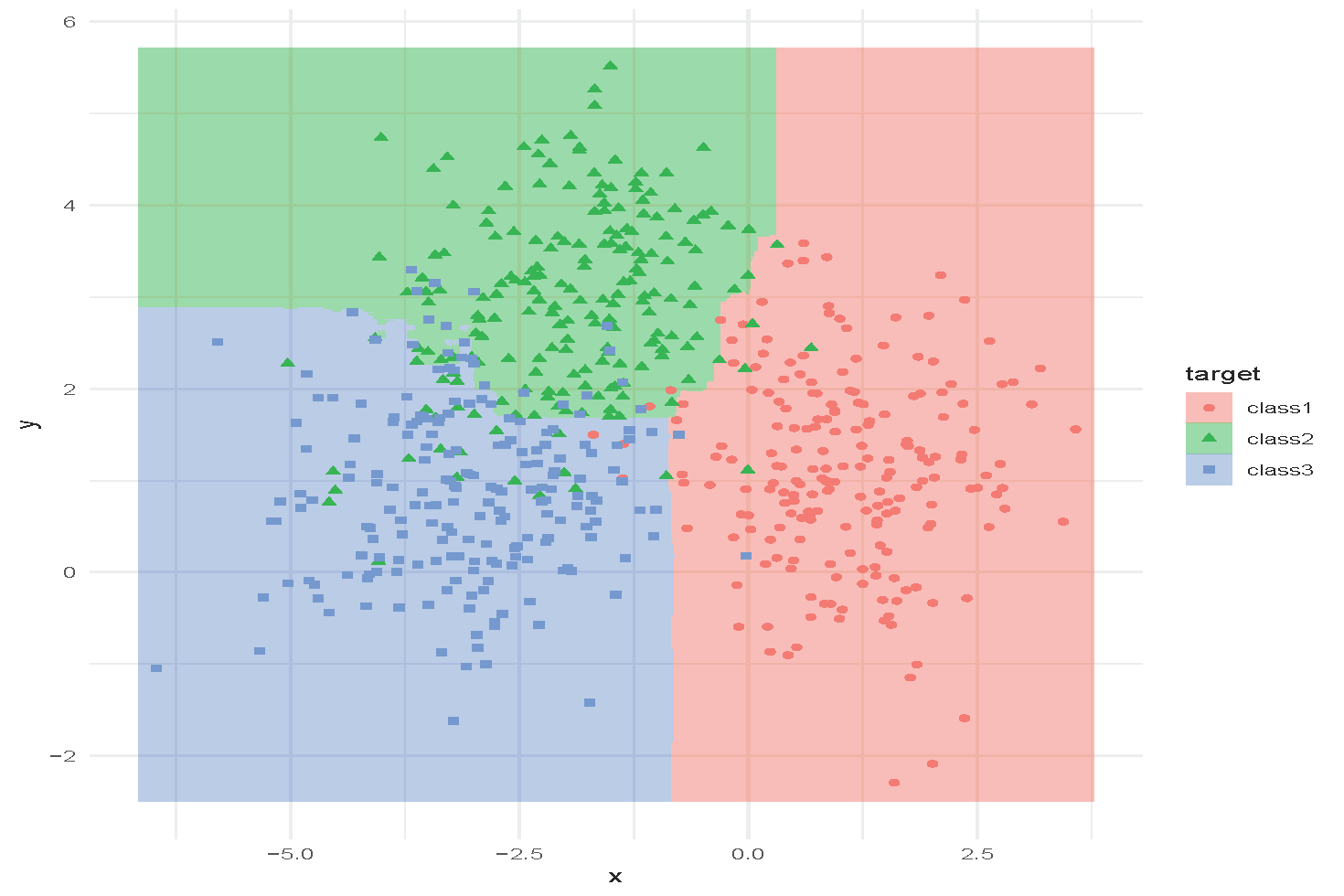
Random forest with n_{\text{trees}} = 1000 and minimum node size = 20.
Example: OOB Error and Test Error
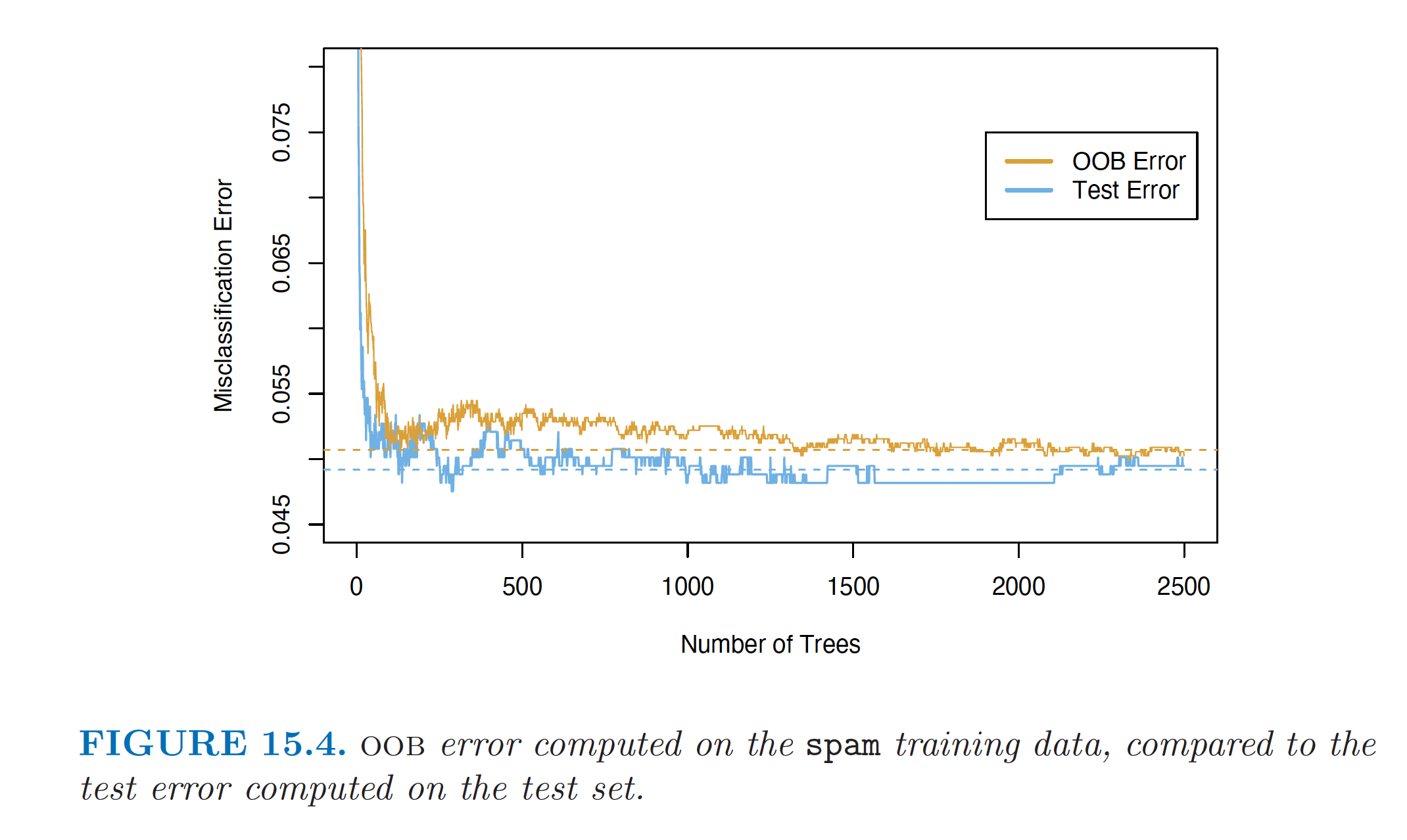
OOB error vs. test error (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 15.4).
Example: Feature Importance
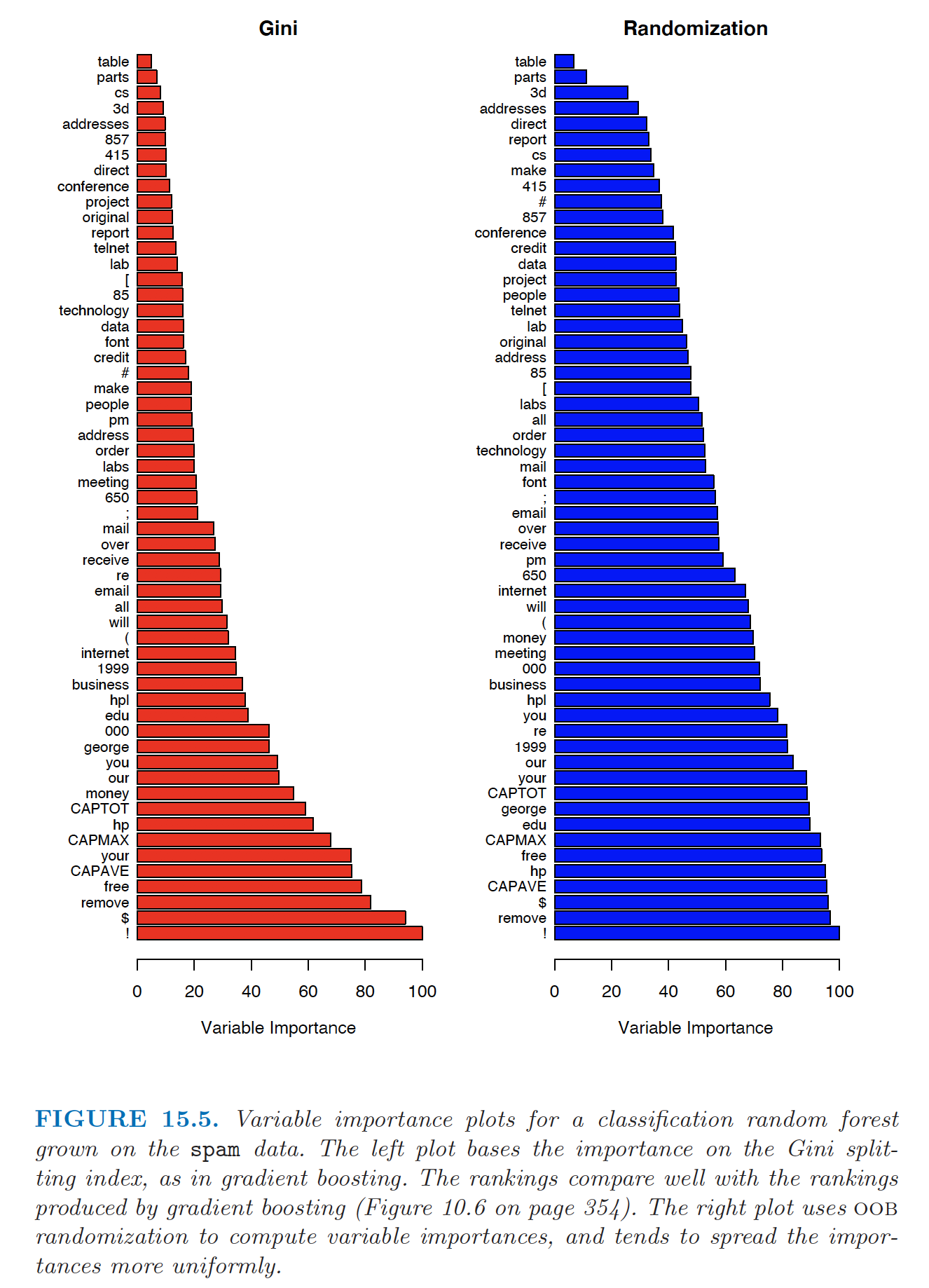
Feature importance based on Gini index (left) and permutation (right) (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 15.5).
References
![]()