Lecture: Model Assessment and Selection
Actuarial Data Science - Open Learning Resource
No Free Lunch Theorem

No free lunch.
There is no single best model that works optimally for all kinds of problems.
Occam’s Razor

The law of parsimony for problem-solving: “entities should not be multiplied without necessity.”
Model Assessment and Selection (continued)
How can we do this?

- What if there is insufficient data to split into three parts? How much training data is enough?
- Solutions: approximate the validation step
- Analytical approaches: AIC, BIC, MDL, SRM
- Efficient sample re-use: cross-validation, bootstrap
Bias, Variance and Model Complexity
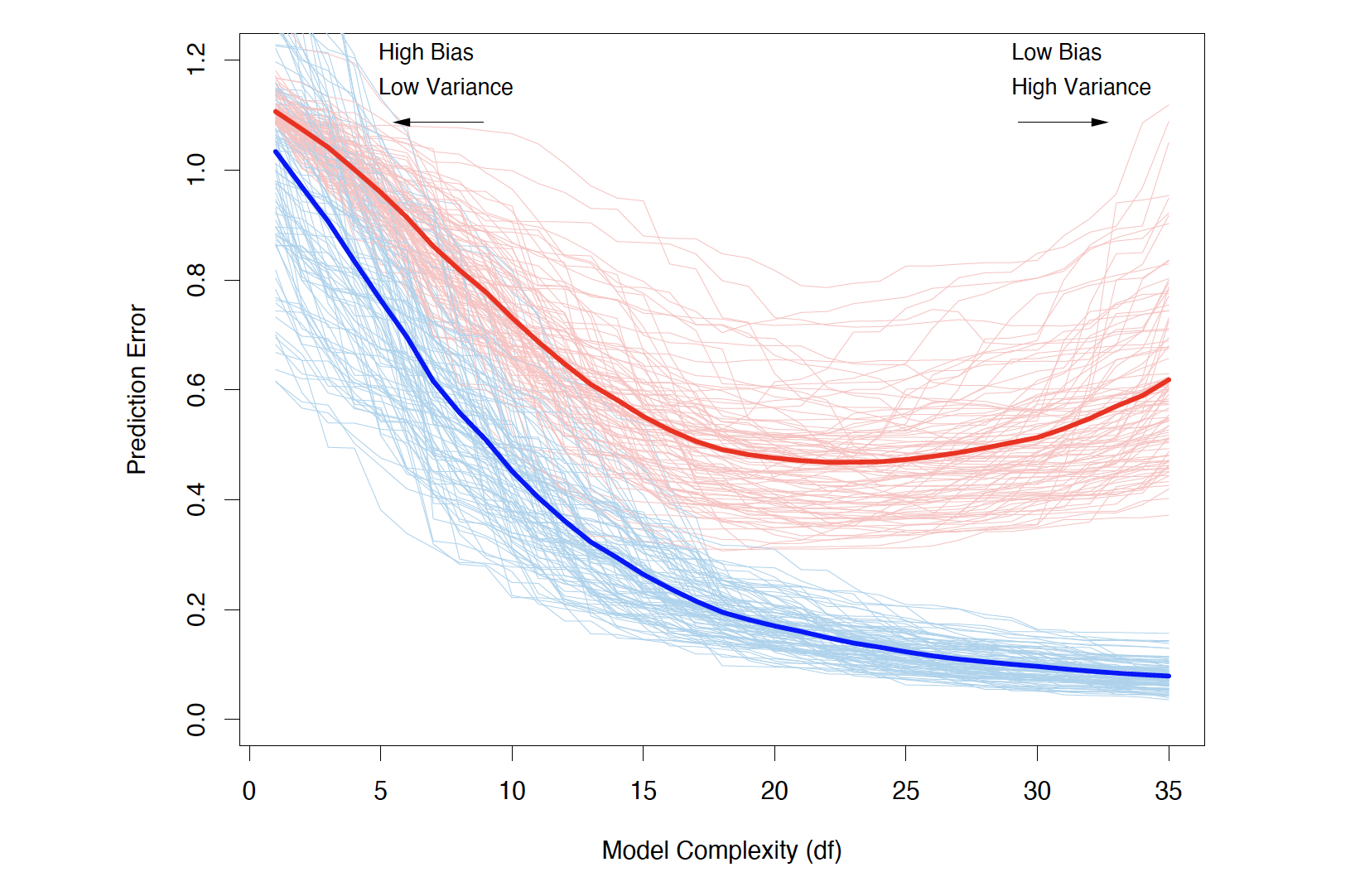
Training and test error as a function of model complexity (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 7.1).
Bias-Variance Trade-off
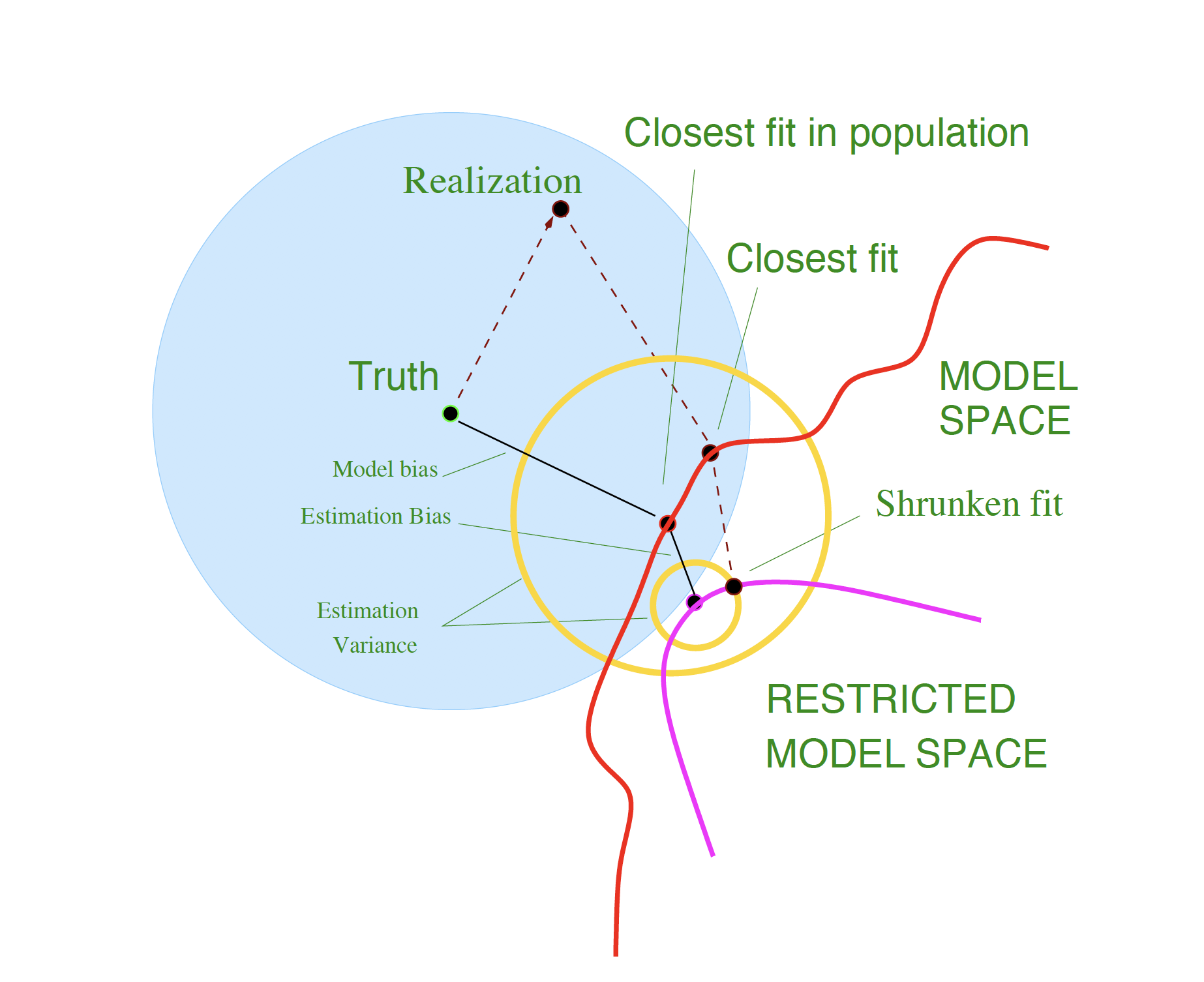
Schematic illustration of the bias–variance trade-off (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 7.2).
Example
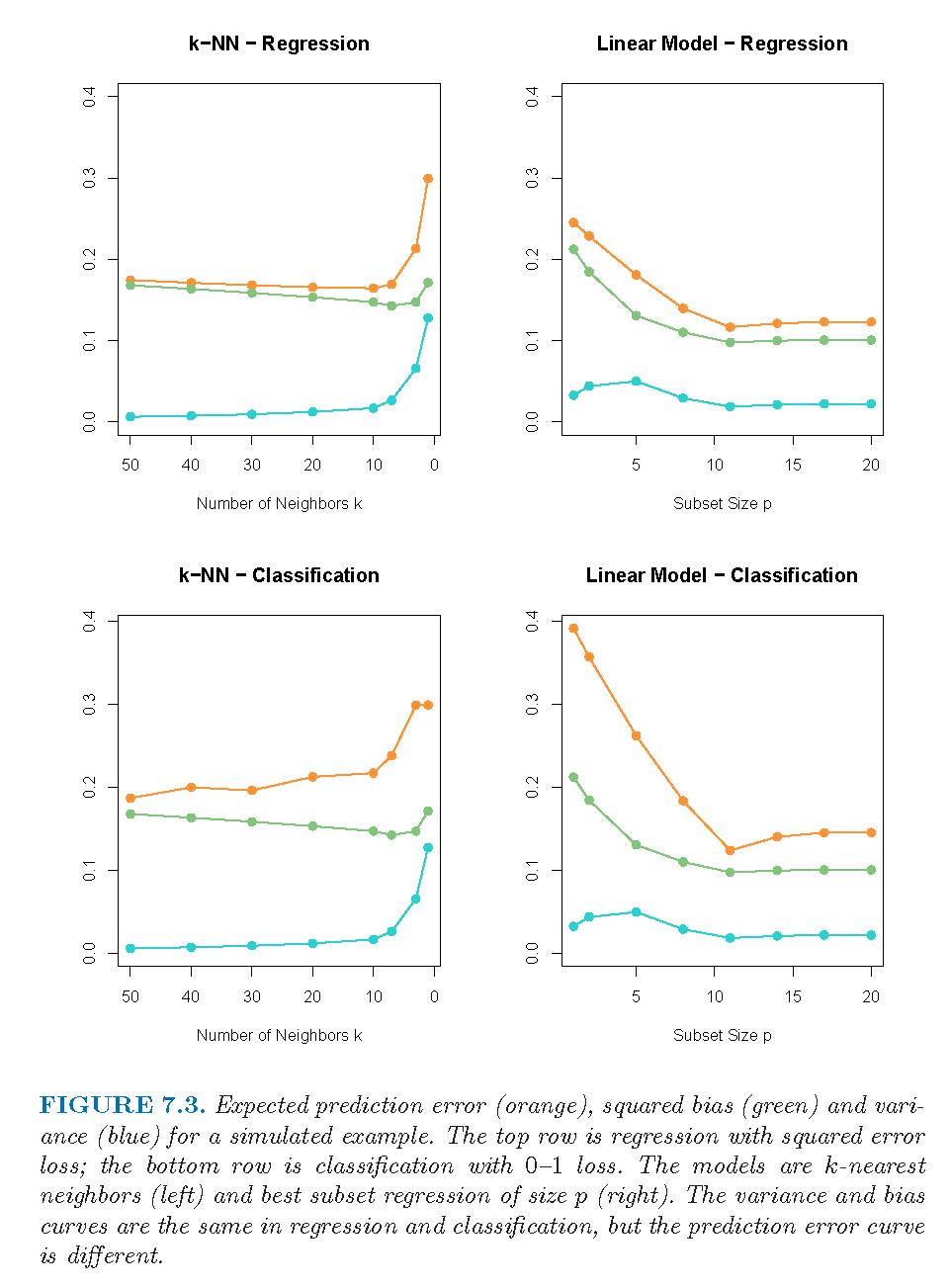
Expected prediction error (orange), squared bias (green), and variance (blue) for k-NN (left) and linear models (right), for both regression (top) and classification (bottom) (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 7.3).
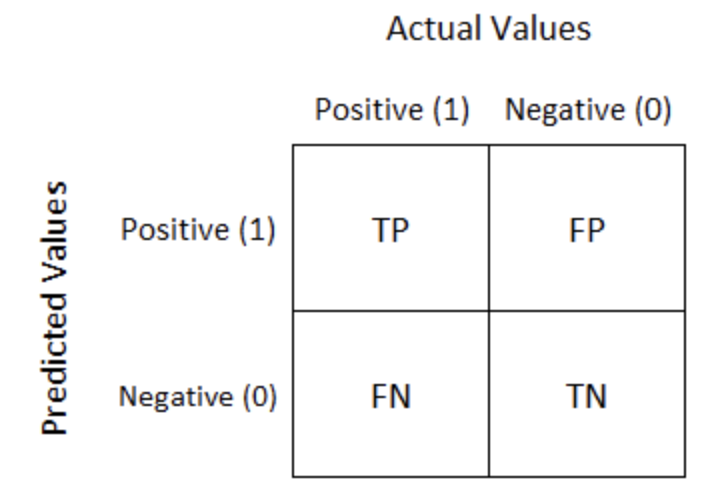
Model Performance of Classification Models
Performance Measures:
AIC/BIC for logistic regression
\text{Accuracy} = \dfrac{TP + TN}{TP + FP + TN + FN}
- Not suitable for imbalanced class distributions
\text{Recall} = \dfrac{TP}{TP + FN}
- Important when the cost of false negatives is high (e.g. cancer screening)
\text{Precision} = \dfrac{TP}{TP + FP}
- Important when the cost of false positives is high (e.g. email spam detection)
\text{F1-score} = \dfrac{2 \cdot \text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}}
- Balances precision and recall
ROC curve / Area under the ROC curve (AUC)
Review: An Introduction to Statistical Learning (James et al. 2013), Section 4.4
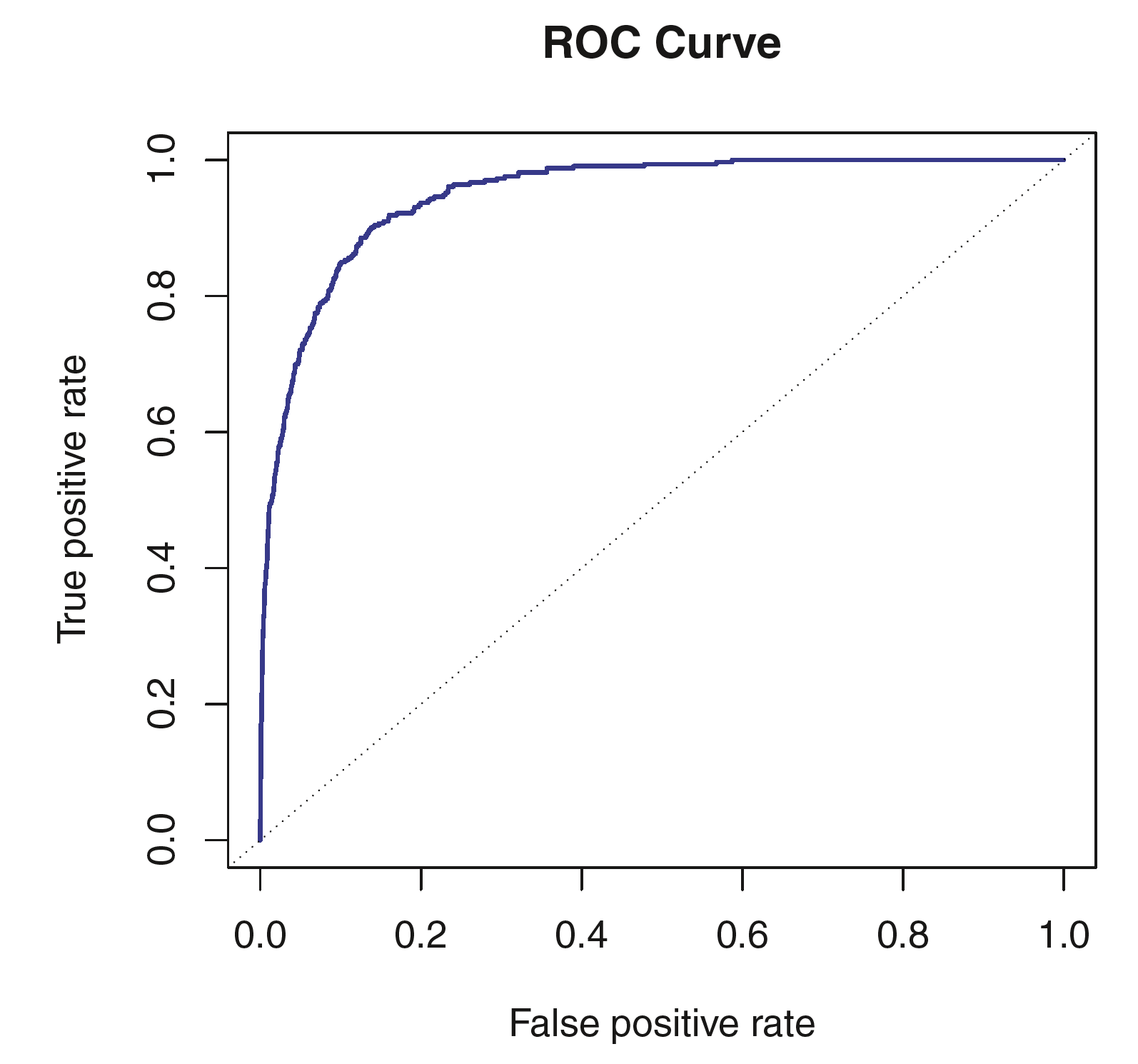
Different Scenarios
- Scenario 1: Train a simple model (no hyperparameters)
- Training + Testing
- Scenario 2: Train a model and tune its hyperparameters
- Validation set approach or cross-validation
- Scenario 3: Compare different models (with hyperparameters), e.g. Random Forest vs Neural Network
- nested cross validation
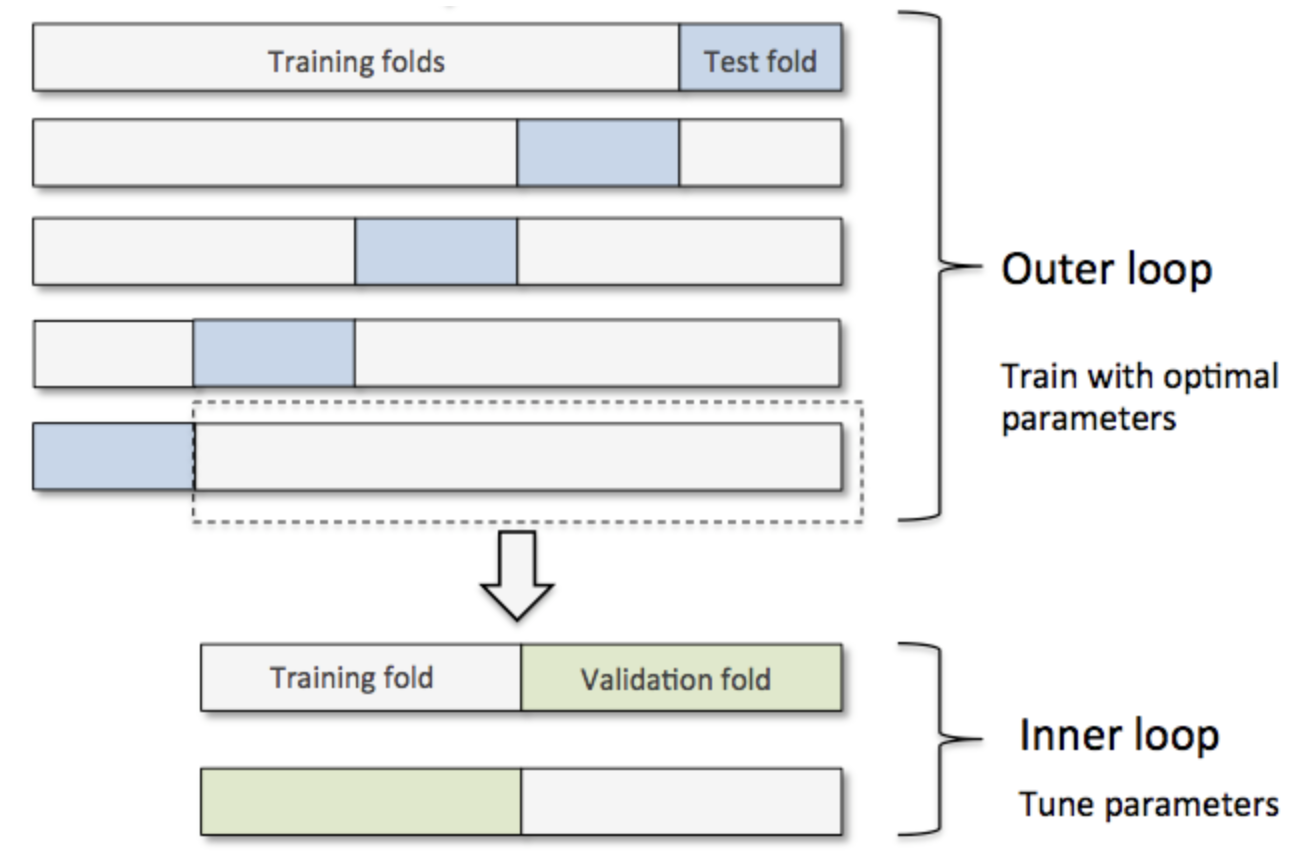
Illustration of nested cross-validation (Source: Raschka (2018)).
- The appropriate approach depends on the problem and the available data.
Bootstrap (continued)
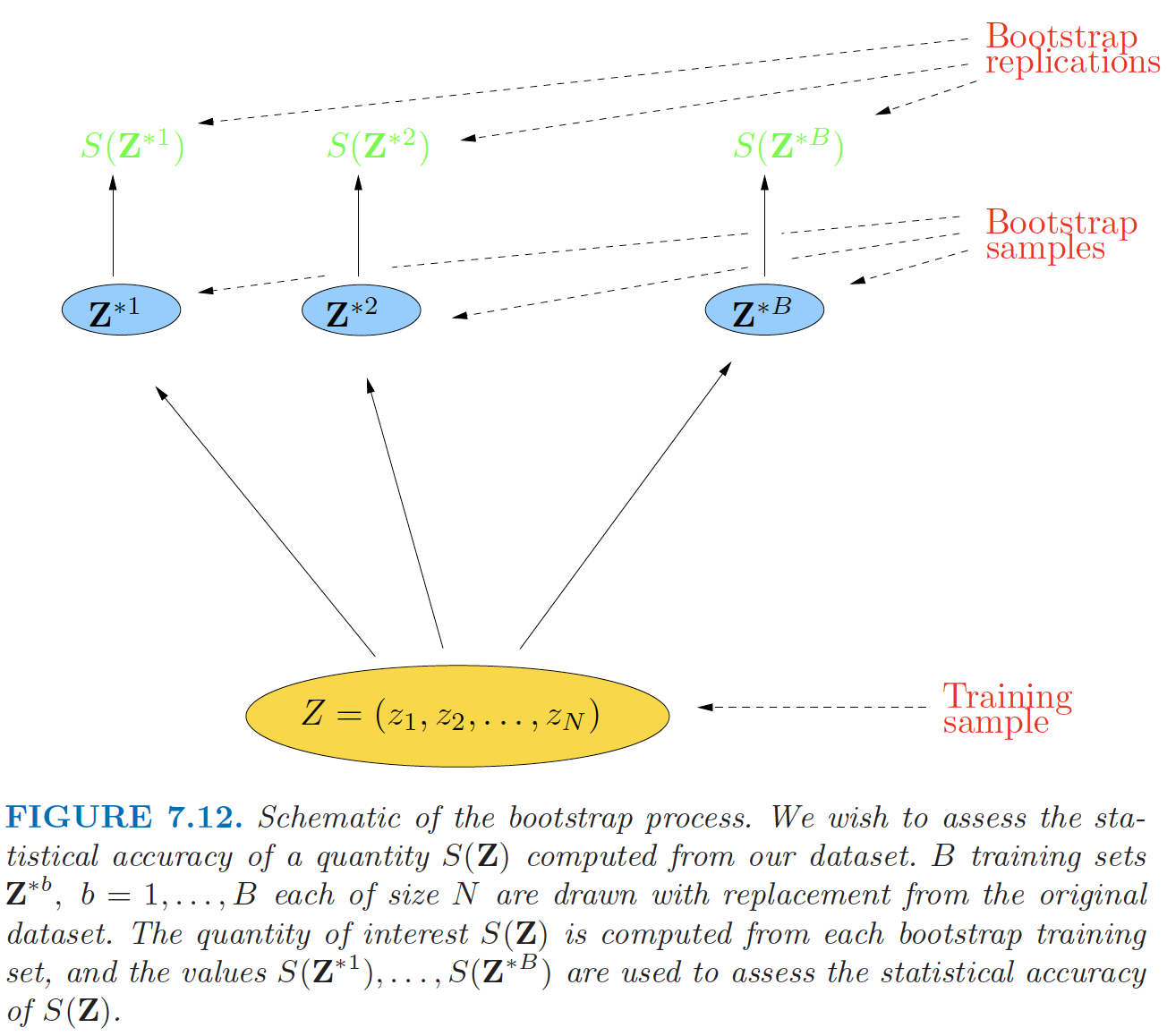
Bootstrap sampling illustration (Source: The Elements of Statistical Learning (Hastie et al. 2009), Figure 7.12).
References
![]()